- The strange case of OrientDB and graph databases
- An overview of OrienDB’s capabilities
- Going beyond RDBMS
- Just like any other NoSQL database?
This post is part of the ”OrientDB 101” series, derived from a previous work started in 2013/2014: some information might be outdated, but the core of this series should still be intact.
Here is a list of all the articles in this series:
In the previous post of this series we saw a few features that make NoSQL storage engines different from RDBMS and we anticipated that OrientDB goes beyond both relational and non-relational system.
What makes this document-oriented NoSQL graph database so different from other non-traditional engines?
Multi-protocol support
First of all, as we already saw, OrientDB supports 2 different protocols, binary and HTTP.
The difference, here, is that since these interfaces are extremely important for different cases, they both share the – almost – same amount of features, and there is no standard protocol defined by the development team, although the binary protocol is the most popular as the native Java API works through it.
While a product like CouchDB only supports the HTTP protocol and MongoDB
weakly supports it1, one of the key features of OrientDB is to almost
1:1 map the functionalities you can access via the binary protocol on
the HTTP one: an example of this is the support of stored procedures,
called functions, available over both protocols.
But multi-protocol support is not OrientDB’s killer feature, as it’s pretty easy to achieve and doesn’t really innovate the way we intend storage engines – it is, however, a good example of Programming By Adapters.
Object-oriented model
Another interesting feature we are going to take a look at is the object-oriented implementation under the document DB: with OrientDB you are able to define a hierarchy between tables (they are called “classes”) and thus being able to take advantage of inheritance.
Since a practical example is worth a million words, suppose you have a collection of animals and want to iterate through them and output their call. With some pseudo-code, your Animal interface and implementing classes would look like
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
The question is, how would you represent animals in the DB?
The code itself is clean, but the data in the DB would lack of differentiation:
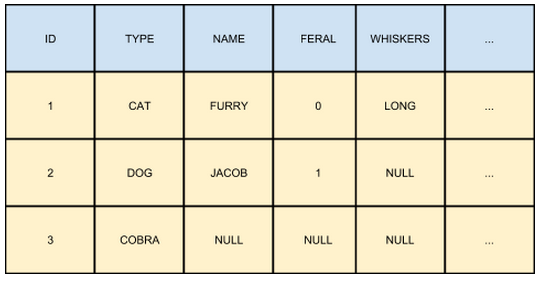
As you see, different animals with different characteristics are represented together in the same table, which is half empty since lots of attributes don’t make sense for most animals: dogs don’t have whiskers, while snakes like cobras, not being domestic, don’t usually have names.
Representing data in this way is a bad smell (called NULLfull antipattern, as it leads to records full of NULL attributes), but having different tables is not always a viable solution:
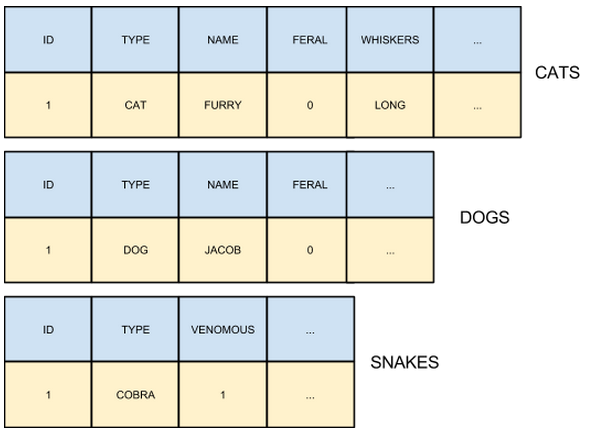
What if you need to look for all animals with a name starting
with the letter J ?
You would need to do N queries (given
N as the number of tables representing animals with the “name”
attribute) and then merge the result or use some special
operator provided by the DBMS itself – with MySQL, for example,
you could use a UNION, but it wouldn’t be much practical.
In OrientDB we can take advantage of the OO support for this
exact scenarios, as you can simply create N classes (Cat, Dog, …)
which extend a parent class (Animal) and run a query on the parent class:
1
| |
You don’t have to create a “master class” containing all the
possible attributes for every subclass which are mostly going
to be NULL (thing that you can do with any document-oriented
storage engine) but at the same time this query will return
results from the Animal class and its subclasses, like no other
document database, as they are not capable to isolate and group
classes via inheritance.
ACIDity
One of the greatest peculiarities of OrientDB is the fact that it melds together new concepts – taken from both the graph and NoSQL world – and old ones, providing a unique tool that can be used in many situations: as a matter of fact, for example, we’ve just seen how it implements OO concepts in its engine, which is a model that object databases first introduced in the late ‘80s.
In the context of applying old but valuable patterns to modern tools, OrientDB doesn’t stop here: ACIDity is one of the core concepts of OrientDB, and is rarely found in other NoSQL databases.
Being ACID allows OrientDB to be considered an enterprise product, as often it is a mandatory requirements in storage engines: consider violating atomicity in a banking environment, where a transaction which consists in 2 operations, deposit and withdrawal, would just run a partial update – ending in a bank account having too much or less money, simply unacceptable.
Following the philosophy of re-using good implementations, patterns and practices, OrientDB supports a syntax which is very similar to SQL:
1
| |
As you see here we are executing a SELECT, retrieving a single
field – (name) with an alias (aliased_name) from a class (Person):
in RDBMS we would talk about selecting a column from a table,
but the main idea is that you can easily write OrientDB’s pseudo-SQL
queries if you have a good SQL background: this has been a wise
choice made by the development team to ensure that most programmers
would find themselves in a sweet spot when dealing with
a pretty new and innovative tool.
Support for relations: linked data
Last but not least, in the previos posts we saw that even if it isn’t a relational database, OrientDB provides support for linked data, as it eventually is a graph database.
Coming from the relational world, you would ask yourself how a JOIN looks like:
1
| |
In the above example, we are joining 2 classes – pet and owner –
via the . operator: OrientDB embeds pointers to other
records directly in the record themselves, and you can access
the related records with the embedded field’s name (owner):
the properties of the related record are accessed with the dot
and the example means “select the first name of the owner of
a pet named Snoopy”. While we are directly querying on a class
(pet) we can access related records without the complexity
of a JOIN.
In SQL we would need to write something like:
1 2 3 | |
As you see, the way OrientDB handles JOINs lets you save a lot of time and results in being very intuitive when you are reading queries, without any tradeoff: what you call JOINs in RDBMS are called LINKs, or edges, in OrientDB.
But if OrientDB supports relational data, why is it classified as a NoSQL storage engine?
The answer is not trivial, and its the subject of the next post of this series.
- through Mongo Wire protocol (http://www.mongodb.org/display/DOCS/Mongo+Wire+Protocol) or via the simple REST interface (http://www.mongodb.org/display/DOCS/Http+Interface#HttpInterface-JSONinthesimpleRESTinterface) ↩