- The strange case of OrientDB and graph databases
- An overview of OrienDB’s capabilities
- Going beyond RDBMS
- Just like any other NoSQL database?
This post is part of the ”OrientDB 101” series, derived from a previous work started in 2013/2014: some information might be outdated, but the core of this series should still be intact.
Here is a list of all the articles in this series:
To let you immediately understand the uniqueness of this product we will briefly list some of its most interesting features: far for being an exhaustive overview, the following list will introduce you to some of the most interesting peculiarities that this DBMS brings into the table.
Graphs everywhere
It is always difficult to understand what “being a graph database” means: simplifying outrageously, we would now define graph DBs as databases which can handle relationships in an easier and faster way compared to traditional databases.
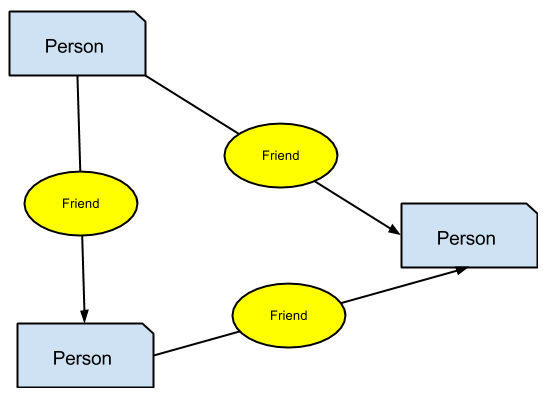
For example, let’s suppose that we have a dataset composed
of many Person (vertexes of the graph) connected by a relationship
named Friend (edges connecting those vertexes).
How can we find all the people connected to me through my friends?
In OrientDB, you would write a SQL-similar query like:
1
| |
which basically means: select all attributes of the records
of type Person that you will find while traversing all the
relations of the record with the given RECORD_ID; in others
words, we are retrieving all the Persons linked to a record,
while traversing the graph: if, as proposed before, the graph
is made of Person connected by a Friend relationship (n:m relation),
the result would include all the people that are connected to the
person identified with the RECORD_ID, at any level of depth – direct
friends, friends of friends and so on.
Being a bit more pragmatic, if you add the $depth parameter you
would be able to retrieve people until a certain level of depth
in the graph:
1 2 | |
What will this query retrieve? All the friends of the friends of
the person identified by the RECORD_ID, since they are 2 steps
(of depth) distant from that person: one step is made to retrieve
that person’s direct friend, the second one to retrieve the direct
friends of his friends.
Needless to say, this kind of query might sound a bit unfamiliar to the reader but, upon a second look, you will realize that is very much SQL-like: another powerful feature of OrientDB, in fact, is its query language, an enhanced version of the usual SQL.
OrientDB, as said, belongs to the family of graph databases, but also breaks the paradigm behind traditional graph DBs by throwing into the table some more powerful layers that are less common to engines of this type: for example, it handles vertexes and edges as documents, as we are about to read in the next section.
Documents
Under the graph layer, OrientDB provides a very powerful document DB that is comparable to what products like MongoDB and CouchDB offer: one of the greatnesses of document DBs, also available in OrientDB, is the usage of documents.

Assuming that you have experienced RDBMS at least once in your career, you will definitely sound familiar with the concept of schema, tables, columns and rows: a schema defines columns in tables and the tables available in a DB, tables aggregate rows, rows represent a record of the dataset and columns the attributes of each row; all of this might sound exciting if you have prior knowledge of your data-structure, but what happens if you are, for example, dynamically storing records you are being sent over an API?
Once the API changes – adding new attributes to its records and so on – your application will either crash due to unpredicted conditions or simply ignore the changes, a situation that can be avoided using documents: instead of behaving like rows with their predefined structure, documents are schema-free records, that can be filled with whatever data is inserted in each of them. Since they don’t need a pre-defined data-structure, documents are very useful to handle fuzzy domains and unpredictable integrations.
Getting back to our Person class (a class is the equivalent of a
table, in OrientDB), we can insert into the class as many records
as we want, with their own attributes:
1 2 | |
and query on them with any of the fields, even if they are only present in a single document of the collection:
1
| |
It’s really interesting to understand how the graph layer of OrientDB is fully based on the document one. As a matter of fact, when you create a vertex in the graph:
1
| |
you are just using the graph syntax instead of the document one:
1
| |
Of course, OrientDB is primarily a graph DB, but nothing should prevent us to understand that, under certain conditions, OrientDB can serve as a document one, replacing solutions like MongoDB.
SQL+
We already introduced a bit of OrientDB’s query language – which I like to call SQL+ – so you might have already appreciated it for how similar it is to the traditional SQL: thanks to this, the transition from a RDBMS like MySQL to OrientDB, as far as the developers are concerned, is not very difficult.
For example, if you need to retrieve the name and age attributes
of records in the class Person, you would write a fully SQL-compliant
query:
1
| |
Given the easiness with which we can start querying the DB, OrientDB shouldn’t be considered as a speed bump for a developer’s learning curve: sure, it has some additional operators and its own syntax to perform certain operations (like traversals), but when you first face OrientDB, writing your first queries, understanding the model and starting to implement CRUD operations over your graph won’t be a slowing factor in your work.
Luckily, OrientDB doesn’t stop at providing support for the old-fashioned SQL syntax, since it also brings some other small – but very convenient – shortcuts that let developers save time while querying the DB.
For example, the star operator is never mandatory:
1
| |
Note the missing star in the query: in SQL you would need to include
it, writing SELECT * FROM Person.
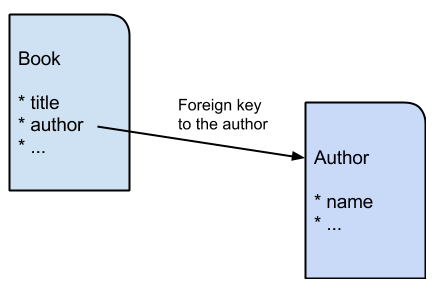
Another very convenient improvement that the authors OrientDB have done
to its query language is the way to deal with JOINs: suppose that you
have a class Book that as a 1:1 relation with records of class
Author, you would have an attribute named “author” in each Book
record that is basically a foreign key to the Author:
As said, JOINing will be pretty easy, as it’s a matter of a “dot”:
1
| |
In this case, we are selecting from the collection Book, filtering,
using a JOIN (author.name), by the author’s name: as you see, there
is no need to even use the JOIN operator or define which fields link
the two records, thing that in a traditional RDBMS would be expressed
as SELECT * FROM Book JOIN Author ON (Book.author = Author.id).
As fast as we can
Performance is a first-class citizen in OrientDB: internal benchmarks have shown that it can serve up to 10 thousand records per second with in-memory DBs (which are not persisted to the disk) while with disk-persisted DBs it performs slightly worse (9.7k GET requests served per second): the difference , of course, is due to the fact that a DB which lies in-memory doesn’t need disk access, but will be completely flushed upon every OrientDB’s restart.
If you might consider this numbers as biased, like every benchmark, even more impressive results have come from the graph DB community: from the laboratories of IBM Research, Toyotaro Suzumura and Miyuru Dayarathna presented a paper, in late 2012, which shows incredible numbers: OrientDB surpasses Neo4j’s – the enterprise-ready and most famous graph DB available in the market as of today – performances, on all tests, by a factor of 10; it basically means that what is considered to be the “best” graph DB in the market is not even comparable, on a performance basis, to OrientDB: sure, Neo4j is by far a more stable and established product in this market, but this benchmark shows how revolutionary OrientDB is.
The key: index-free adjacency
Marko Rodriguez, an influential personality in the graph DB ecosystem, once defined graph DBs as databases which provide index-free adjacency between records: this means that once you have a record, to access related records you don’t have to lookup relations in a index – like in traditional RDBMS – since relations are self-contained in the records themselves.
If you think that this is a small peculiarity, you couldn’t be more wrong: having self-contained relations means that to move from a record to another one will always have a constant cost, no matter how big the graph is: on the other end, RDBMS, once they start having a big amount of records, tend to highly worsen in terms of performances, since their indexes – and the lookups associated to them – grow logarithmically; in graph DBs, the cost is constant instead.
The speed and performances analyzed in the previous sections are also a result of OrientDB’s index-free implementation: even though this is common to any graph database, OrientDB focuses on performances and it has been built to extremely optimize data retrieval operations.
Inheritance
You may have heard of object databases, which try to bring object-oriented concepts into storage engines: like them, OrientDB integrates quite a few concepts from the OO world.
Probably the most powerful of them, inheritance, helps classifying records and gives more granularity to the schema, by allowing the developer to create classes that inherit from other classes.
For example, given that we have a class Car and a class
Bike which extend from Vehicle and have a 1:1 relationship
with records of the class Person, it would be very easy to
retrieve records all the vehicles that belong to a person:
1
| |
The above query would return you all vehicles (bikes as well as cars) that belong to a particular person.
HTTP interface
Another curious peculiarity of OrientDB is that it offers two protocols to interact with it, a binary one and an HTTP interface that is very easy to interact with. Surely, the binary protocol is faster than the HTTP one, but at the same time the advantage of using the latter comes out in terms of simplicity; in order to start querying the database, for example, you would just nee d a simple cURL command:
1 2 | |
In the example above you would be running the query
SELECT FROM Person on a DB named demo: note that the user admin
should have rights to actually access the database (this happens for the
default DBs included in each OrientDB’s distribution).
OrientDB’s HTTP interface is pretty complete, as you can create classes, manipulate records and so on through it: if you want to get more information on the available APIs I would recommend you to have a look at the documentation.
ACID
A lot are quite skeptic towards NoSQL databases as they would argue that they can’t be use in a few context where acidity matters: for example, being unable to support transactions, MongoDB would never be a suitable candidate in a banking environment.
ACIDity, instead, is implemented by OrientDB, which means that the storage engine is:
- Atomic, supporting transaction
- Consistent, with DBs never ending up in a corrupted state
- Isolated, so concurrent transactions execute as if they were in series
- Durable, so once transaction are applied, they can’t be reverted by a fault in the system
Summary
If you individually take each of this feature, you won’t get excited, as most of the products in the DB market implement a few of them, but being able to meld down all of them together OrientDB is simply something that no developer has ever seen before; in his brief history, it has gained so much attention that almost everyone in the NoSQL ecosystem is looking at this new competitor with a curious eye.
OrientDB won’t be your swiss-army knife, is not going to be the one-size-fits-all tool you always needed and never found before: it is a new way to think about data in our times, a way that has its own boundaries and scopes, and this series I’m writing will give you an overview of the goods of OrientDB as well as the commonly-accepted anti-patterns when dealing with RDBMS.
On top of this, OrientDB is not only a NoSQL database: it’s a mixture of RDBMS, NoSQL databases and eventually a graph DB; what makes this product so interesting is that it melds together 3 worlds as it never happened before.
And to clarify the previous statement, in the next article we are going to take a look at the differences between OrientDB and traditional RDBMS, what makes it so special when compared with other NoSQL products and and understand in which scenarios OrientDB would fit our requirements.