- Web security demystified: WASEC
- Introduction
- Understanding the browser
- Security at the HTTP level
- HTTP headers to secure your application
- Hardening HTTP cookies
- Situationals
This post is part of the ”WASEC: Web Application SECurity” series, which is a portion of the content of WASEC, an e-book on web application security I’ve written.
Here is a list of all the articles in this series:
If you’ve enjoyed the content of this article, consider buying the complete ebook on either the Kindle store or Leanpub.
Often times, we’re challenged with decisions that have a direct impact on the security of our applications, and the consequences of those decisions could potentially be disastrous. This article aims to present a few scenarios you might be faced with, and offer advice on how to handle each and every single of them.
This is by no means an exhaustive list of security considerations you will have to make in your day to day as a software engineer, but rather an inspiration to keep security at the centre of your attention by offering a few examples.
Blacklisting versus whitelisting
When implementing systems that require discarding elements based on an input (eg. rejecting requests based on an IP address or a comment based on certain words) you might be tempted to use a blacklist in order to filter elements out.
The inherent problem with blacklist is the approach we’re taking: it allows us to specify which elements we think are unsafe, making the strong assumption of knowing everything that might hurt us. From a security perspective, that’s the equivalent of us wearing summer clothes because we’re well into June, without looking out the window in order to make sure today’s actually sunny: we make assumptions without having the whole picture, and it could hurt us.
If you were, for example, thinking of filtering out comments based on a blacklist of words, you would probably start by describing a blacklist of 5 to 10 words: when coming up with the list you might be forgetting words such a j3rk, or reject genuine comments mentioning “Dick Bavetta”, a retired NBA referee.
Now, comments aren’t always the most appropriate example in terms of security, but you get the gist of what we’re talking about: it’s hard to know everything that’s going to hurt us well in advance, so whitelisting is generally a more cautious approach, allowing us to specify what input we trust.
A more practical example would be logging: you will definitely want to whitelist what can be logged rather than the opposite. Take an example object such as:
1 2 3 4 5 6 | |
You could possibly create a blacklist that includes password and credit_card, but what would happen when another engineer in the team changes fields from snake_case to camelCase?
Our object would become:
1 2 3 4 5 6 | |
You might end up forgetting to update your blacklist, leading to the credit card number of your customers being leaked all over your logs.
As you’ve probably realized, the choice of utilizing a blacklist or a whitelist highly depends on the context you’re operating in: if you’re exposing a service on the internet (such as facebook.com), then blacklisting is definitely not going to work, as that would mean knowing the IP address of every genuine visitor, which is practically impossible.
From a security perspective, whitelisting is definitely a better approach, but is often impactical. Choose your strategy carefully after reviewing both options: none of the above is suitable without prior knowledge of your system, constraints and requirements.
Logging secrets
If you develop systems that have to deal with secrets such as passwords, credit card numbers, security tokens or personally identifiable information (abbr. PII), you need to be very careful about how you deal with these data within your application, as a simple mistake can lead to data leaks in your infrastructure.
Take a look at this example, where our app fetches user details based on a header:
1 2 3 4 5 6 7 8 | |
Now, this innocuous piece of code is actually dangerous: if an error occurs, the entire request gets logged.
Having the whole request logged is going to be extremely helpful when debugging, but will also lead to storing auth tokens (available in the request’s headers) in our logs: anyone who has access to those logs will be able to steal the tokens and impersonate your users.
You might think that, since you have tight restrictions on who has access to your logs, you would still be “safe”: chances are that your logs are ingested into a cloud service such as GCP’s StackDriver or AWS’ CloudWatch, meaning that there are more attack vectors, such as the cloud provider’s infrastructure itself, the communication between your systems and the provider to transmit logs and so on.
The solution is to simply avoid logging sensitive information: whitelist what you log (as we’ve seen in the previous paragraph) and be wary of logging nested entities (such as objects), as there might be sensitive information hiding somewhere inside them, such as our req.headers.token.
Another solution would be to mask fields, for example turning a credit card number such as 1111 2222 3333 4444 into **** **** **** 4444 before logging it.
That’s sometimes a dangerous approach: an erroneous deployment or a bug in your software might prevent your code from masking the right fields, leading to leaking the sensitive information. As I like to say: use it with caution.
Last but not least, I want to mention one particular scenario in which any effort we make not to log sensitive information goes in vain: when users input sensitive information in the wrong place.
You might have a login form with username and password, and users might actually input their password in the username field (this can generally happen when you “autoremember” their username, so that the input field is not available the next time they log in). Your logs would then look like this:
1 2 3 | |
Anyone with access to those logs can figure an interesting pattern out: if a username doesn’t follow an email pattern ([email protected]), chances are the string is actually a password the user had wrongly typed in the username field. Then you would need to look at the successful login attempts been made shortly after, and try to login with the submitted password against a short list of usernames.
What is the point here? Security is hard and, most often, things will work against you: in this context, being paranoid is a virtue.
Who is silly enough to log a password?
You might think logging sensitive information is an amateur’s mistake, but I argue that even experienced programmers and organizations fall fall under this trap. Facebook, in early 2019, suffered a security incident directly related to this problem. As Brian Krebs put it:
“Facebook is probing a series of security failures in which employees built applications that logged unencrypted password data for Facebook users and stored it in plain text on internal company servers.”
This is not to say that Facebook should not be held accountable for the incident, but rather that we can probably sympathize with the engineers who forgot the console.log somewhere in the code. Security is hard, and so making sure we pay extra-attention to what we log is an extremely important matter.
Never trust the client
As we’ve seen before, cookies that are issued by our servers can be tampered with, especially if they’re not HttpOnly and are accesible by JS code on your page.
At the same time, even if your cookies are HttpOnly, storing plaintext data in them is not secure, as any client (even curl), could get a hold of those cookie, modify them and re-issue a request with a modified version of the original cookie.
Suppose your session cookie contains this information:
1
| |
The string is base64-encoded, and anyone could reverse it to get to its actual value, username=LeBron,role=user. Anyone could, at that point, replace user with admin and re-encode the string, altering the value of the cookie.
If your system trusts this cookie without any additional check, you’re in for trouble. You should instead never trust the client, and prevent it from being able to easily tamper with the data you’ve handed off. A popular workaround to this issue is to encrypt or sign this data, like JSON Web Tokens do.
Let’s drift for a second and dive into JWT, as their simplicity lets us understand the security mechanism behind them extremely well. A JWT is made of 3 parts: headers, claims and signature, separated by a dot:
1
| |
Each value is base64-encoded, with header and claims being nothing but an encoded JSON object:
1 2 3 4 5 6 7 8 9 10 11 12 | |
The last part, the signature, is the Message Authentication Code (abbr. MAC) of the combined $HEADER.$CLAIM, calculated through the algorithm specified in the header itself (HMAC SHA-256 in our case). Once the MAC is calculated, it is base64-encoded as well:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
E-voila, our JWT is here!
If you followed this far, you might have understood that JWT is simply composed of 3 parts: 2 insecure set of strings and a signed one, which is what is used to verify the authenticy of the token. Without the signature, JWTs would be insecure and (arguably) useless, as the information they contain is simply base64-encoded.
As a practical example, let’s have a look at this token:
1
| |
As you can see, we have 3 base64-encoded strings, separated by dots. Reversing them in bash is straightforward:
1 2 3 4 | |
As you would expect, the signature produces garbage instead:
1 2 | |
That’s the mechanism JWTs use to prevent clients from tampering with the tokens themselves: when a server validates a token, it will first verify its signature (through the public key associated by the private one used to generate the signature), then access the token’s data. If you’re planning to hand over critical information to the client, signing or encrypting it is the only way forward.
Are JWTs safe?
JWTs have been under a lot of scrutiny in recent years, partly because of some design flaws that had to be course-corrected, such as the support of a ‘None’ algorithm which would effectively allow forging tokens without any prior knowledge of secrets and keys used to sign them. Luciano Mammino, a researcher from Italy, even managed to publish a JWT cracker to illustrate how easy it could be to crack JWTs through brute-forcing, granted the algorithm and secrets used are weak.
In all honesty, JWTs are very useful when you want to exchange data between two parties. For example, you could send a client the URL https://example.com/check-this-message?token=$JWT so that they could access the data within the token and know it comes from a trusted source. As session IDs, often times there are simpler mechanism you should rely on, as you only really need to issue a cryptographically random ID that identifies a client.
Does this mean JWTs are not safe? Not really, as it depends on how you use them: Google, for example, allows authentication to their APIs through JWTs, like many others; the trick is to use safe, long secrets or a cryptographically secure signing algorithm, and understand the use-case you’re presented with. JWTs also don’t make any effort to encrypt the data they hold, and they’re only concerned with validating its authenticity: understand these trade-offs and make your own educated choice.
In addition, you might want to consider PASETO, “Platform Agnostic SEcurity TOkens”: they were designed with the explicit goal to provide the flexibility and feature-set of JWTs without some of the design flaws that have been highlighted earlier on.
Further readings:
Generating session IDs
It should go without saying, but your session IDs (often stored in cookies) should not resemble a know pattern, or be generally guessable. Using an auto-icrementing sequence of integers as IDs would be a terrible choice, as any attacker could just log in, receive session id X and then replace it with X ± N, where N is a small number to increase chances of that being an identifier of a recent, thus valid, session.
The simplest choice would be to use a cryptographically secure function that generates a random string, and usually that’s not a hard task to accomplish. Let’s, for example, take the Beego framework, very popular among Golang developers, as an example: the function that generates session IDs is
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
6 lines of code, secure session IDs. As we mentioned earlier, no magic needs to be involved. In general, in most cases you won’t need to write this code yourself, as frameworks would provide the basic building blocks to secure your application out of the box: if you’re in doubt, though, you can review the framework’s code, or open an issue on GitHub to clarify your security concern.
Querying your database while avoiding SQL injections
Right off the bat, you’re probably thinking: “I’ve heard about injections!”, and that’s probably because was the #1 vulnerability in the “2017 OWASP Top 10: The Ten Most Critical Web Application Security Risks”.
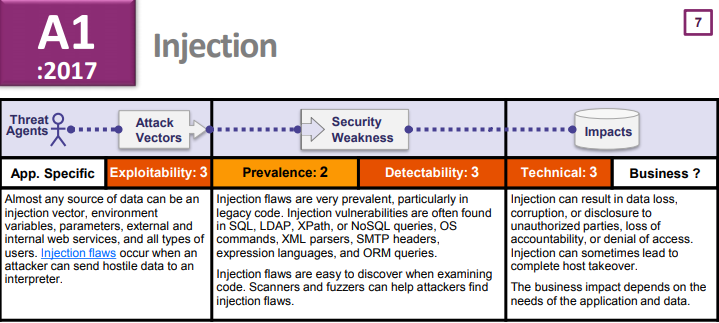
But guess what, injections made the #1 spot in the 2010 and 2013 version of the same list as well, and so there’s a strong chance you might be familiar with any type of injection risk. To quote what we discussed earlier in this chapter, the only thing you need to remember to fight injection is to never trust the client: if you receive data from a client, make sure it’s validated, filtered and innocuous, then pass it to your database.
A typical example of an injection vulnerability is the following SQL query:
1
| |
Suppose $name comes from an external input, like the URL
https://example.com/users/search?name=LeBron: an attacker can then craft a specific value for the variable that will significantly alter the SQL query being executed. For example, the URL https://example.com/users/search?name=anyone%22%3B%20TRUNCATE%20TABLE%20users%3B%20-- would result in this query being executed:
1
| |
This query would return the right search result, but also destroy the users’ table, with catastrophic consequences.
Most frameworks and libraries provide you with the tools needed to sanitize data before feeding it to, for example, a database. The simplest solution, though, is to use prepared statements, a mechanism offered by most databases that prevents SQL injections altogether.
Prepared statements: behind the scenes
Wondering how prepared statements work? They’re very straightforward, but often misunderstood. The typical API of a prepared statement looks like:
query = `SELECT * FROM users WHERE id = ?`
db.execute(query, id)As you can see, the “base” query itself is separated from the external variables that need to be embedded in the query: what most database drivers will eventually do is to first send the query to the database, so that it can prepare an execution plan for the query itself (that execution plan can also be reused for the same query using different parameters, so prepared statements have performance benefits as well). Separately, the driver will also send the parameters to be used in the query.
At that point the database will sanitize them, and execute the query together with the sanitized parameters.
There are 2 key takeaways in this process:
- the query and parameters are never joined before being sent to the database, as it’s the database itself that performs this operation
- you delegate sanitization to a built-in database mechanism, and that is likely to be more effective than any sanitization mechanism we could have come up by ourselves
Dependencies with known vulnerabilities
Chances are that the application you’re working on right now depends on a plethora of open-source libraries: ExpressJS, a popular web framework for NodeJS, depends on 30 external libraries, and those libraries depend on…we could go on forever. As a simple exercise, I tried to install a brand new version of ExpressJS in my system, with interesting results:
1 2 3 4 | |
Just by installing the latest version of ExpressJS, I’ve included 50 libraries in my codebase. Is that inherently bad? Not at all, but it presents a security risk: the more code we write (or use), the larger the attack surface for malicious users.
One of the biggest risks when using a plethora of external libraries is not following up on updates when they are released: it isn’t so bad to use open-source libraries (after all, they probably are safer than most of the code we write ourselves), but forgetting to update them, especially when a security fix gets released, is a genuine problem we face every day.
Luckily, programs such as npm provide tools to identify outdated packages with known vulnerabilities: we can simply try to install a dependency with a known vulnerability and run npm audit fix, and npm will do th job for us.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
If you’re not using JavaScript and npm, you can always rely on external services to scan your software and let you know if any library with known vulnerabilities is found: GitHub offers this service for all their repositories, and you might find it convenient when your codebase is already hosted there.
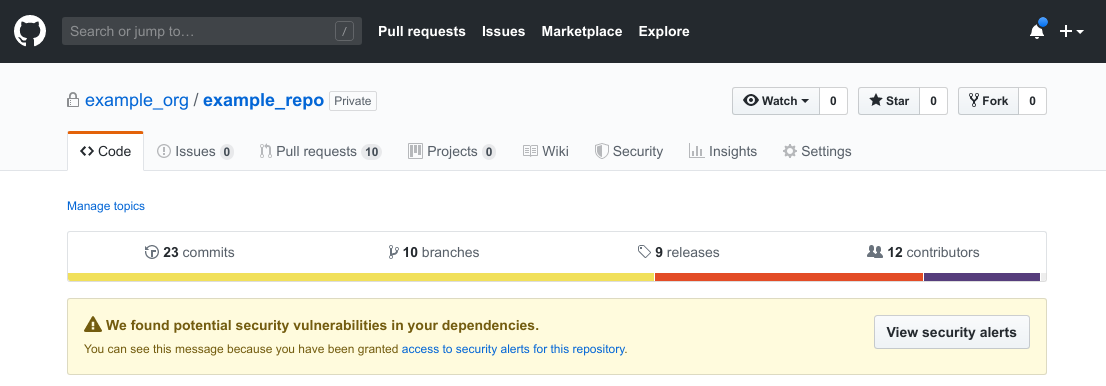
GitHub will also send you an email every time a dependency with a known vulnerability is detected, so you can head over to the repository and have a look at the problem in detail.
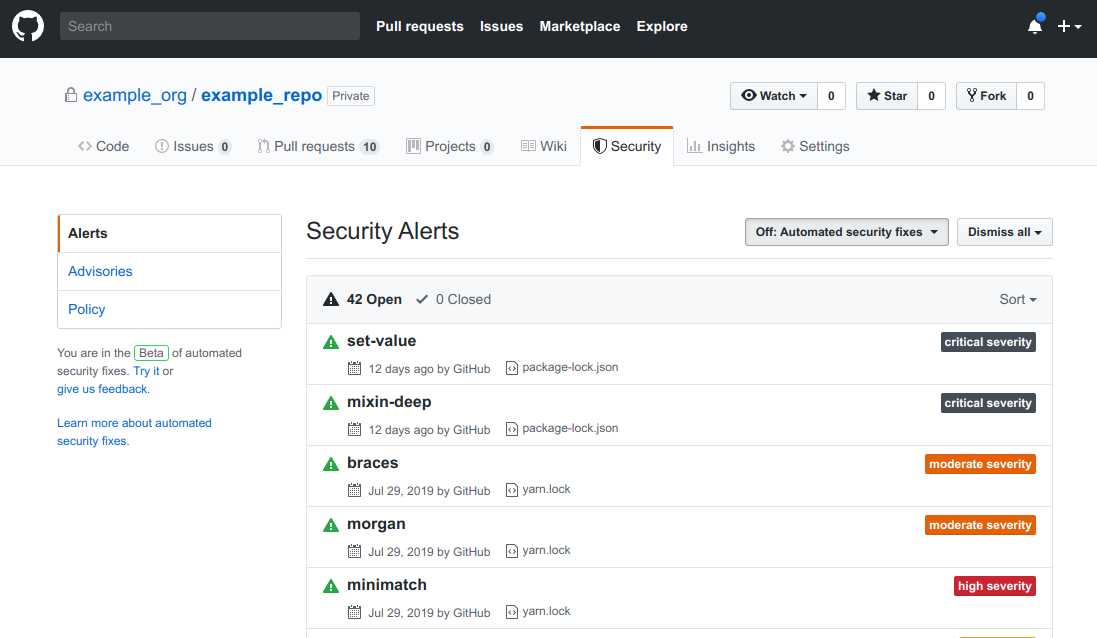
If you prefer using a different platform, you could try gitlab.com: it acquired Gemnasium, a product that offered vulnerability scanning, in early 2018 in order to compete with GitHub’s offering. If you prefer to use a tool that does not require code hosting instead, snyk.io would probably be your best bet: it’s trusted by massive companies such as Google, Microsoft and SalesForce, and offers different tools for your applications, not just dependency scanning.
Have I been pwned?
Remember when you were a teenager, and signed up for your first online service ever? Do you remember the password you used? You probably don’t, but the internet might.
Chances are that, throughout your life, you’ve used an online service that has been subject to attacks, with malicious users being able to obtain confidential information, such as your your password. I’m going to make it personal here: my email address has been seen in at least 10 public security breaches, including incidents involving trustworthy companies such as LinkedIn and Dropbox.
How do I know?
I use a very interesting service called haveibeenpwned.com (abbr. HIBP), created by Troy Hunt, an Australian web security expert. The site collects information about public data breaches and allows you to understand whether your personal information was seen in any of these breaches. There’s no shame in being involved in one of these data breaches, as it’s not really your fault. This is, for example, the result of looking up the email address of Larry Page, one of Google’s co-founders:
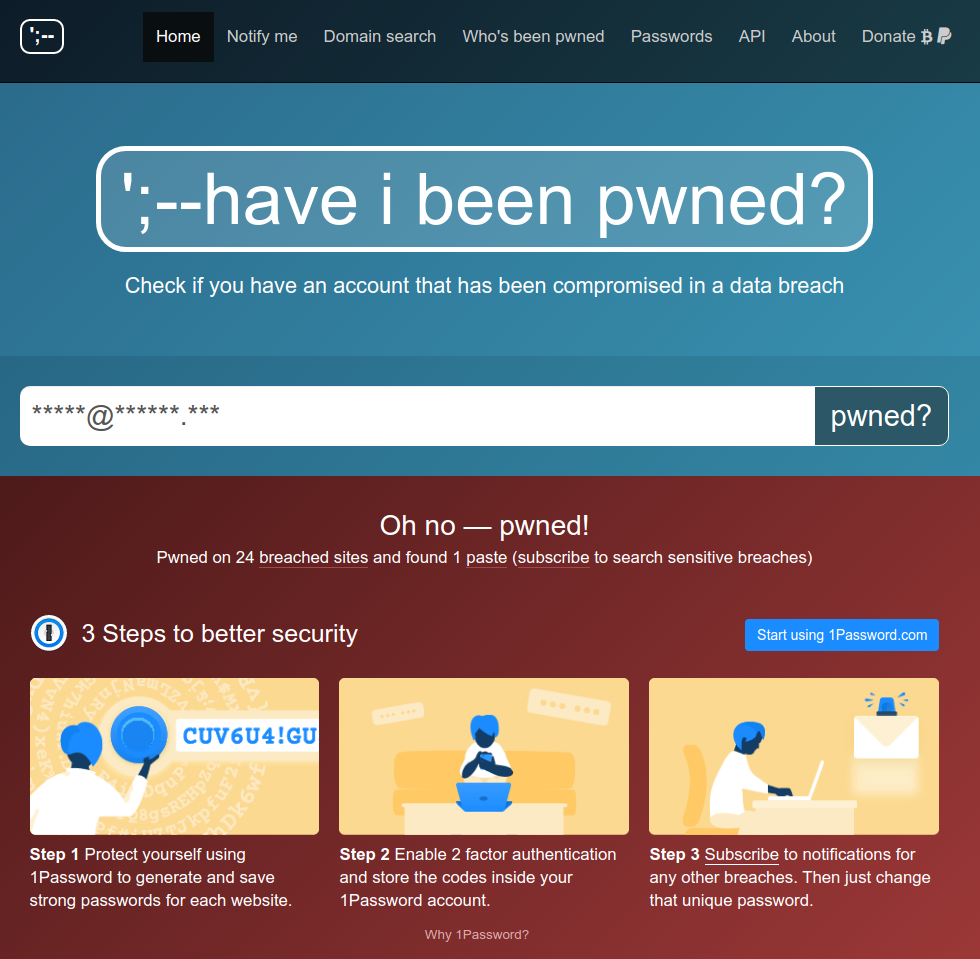
Larry’s email address has been masked, but it’s pretty public information
By knowing when and where an incident happened, you can take a few actions to improve your personal security posture, such as activating two-factor authentication (abbr. 2FA) and being notified of a breach as soon as HIBP is.
One of the interesting side-effects of HIBP is, though, the ability to use it to improve your business’ security, as the site offers an API that you can use to verify whether users within your organization were involved in a data breach. This is extremely important as, too often, users consider security an afterthought, and opt out of mechanisms such as 2-factor authentication. This quickly becomes disastrous when you put in context of password re-use, a practice that is still way too common: a user signing up to multiple services using the same exact password. When one of those services is breached, the accounts on all the other ones might be breached as well.
Re-using credentials: a real-world story
I’ve been directly hit by a password re-use attack during my career, and it wasn’t a fun experience.
While I was heading technology at an online company, our security team received a message from a (questionable) researcher claiming he could login into many of our user accounts, sending across plaintext passwords to prove the fact. Baffled, we quickly realized we either got compromised, or someone else had been: when the attacker revealed *how* he got those credentials, we quickly realized they were available to the public through some hardcore googling.
After obtaining a full list of emails included in the breach, we then had to join it with the list of our customers, ending with forcefully resetting the password of the ones found both in the breach and our own database.
Session invalidation in a stateless architecture
If you’ve ever built a web architecture, chances are that you’ve heard how stateless ones scale better due to the fact that they do not have to keep track of state. That is true, and it represents a security risk, especially in the context of authentication state.
In a typical stateful architecture, a client gets issued a session ID, which is stored on the server as well, usually linked to the user ID. When the client requests information from the server, it includes its session ID, so that the server knows that a particular request is made on behalf of a user with a particular ID, thanks to the mapping between session and user IDs. This requires the server store a list of all the session IDs it generated with a link to the user ID, and it can be a costly operation.
JWTs, which we spoke about earlier on in this chapter, rose to prominence due to the fact that they easily allow stateless authentication between the client and the server, so that the server would not have to store additional information about the session. A JWT can include a user id, and the server can simply verify its signature on-the-fly, without having to store a mapping between a session ID and a user ID.
The issue with stateless authentication tokens (and not just JWTs) lies in a simple security aspect: it is supposedly hard to invalidate tokens, as the server has no knowledge of each one it generated since they’re not stored anywhere. If I logged in on a service yesterday, and my laptop gets stolen, an attacker could simply use my browser and would still be logged in on the stateless service, as there is no way for me to invalidate the previously-issued token.
This can be easily circumvented, but it requires us to drop the notion of running a completely stateless architecture, as there will be some state-tracking required if we want to be able to invalidate JWTs. The key here is to find a sweet spot between stateful and stateless, taking advantage of both the pros of statelessness (performance) and statefulness (security).
Let’s suppose we want to use JWTs for authentication: we could issue a token containing a few information fo the user:
1
| |
1 2 3 4 5 | |
As you can see, we included a the issued at (iat) field in the token, which can help us invalidating “expired” tokens. You could then implement a mechanism whereby the user can revoke all previously issued tokens by simply by clicking a button that saves a timestamp in a, for example, last_valid_token_date field in the database.
The authentication logic you would then need to implement for verifying the validity of the token would look like this:
1 2 3 4 5 6 7 8 9 10 11 | |
Easy-peasy! Unfortunately, this requires you to hit the database everytime the user logs in, which might go against your goal of scaling more easily through being state-less. An ideal solution to this problem would be to use 2 tokens: a long-lived one and a short-lived one (eg. 1 to 5 minutes).
When your servers receive a request:
- if it only has the long-lived one only, validate it and do a database check as well. If the process is successful, issue a new short-lived one to go with the long-lived one
- if it carries both tokens, simply validate the short-lived one. If it’s expired, repeat the process on the previous point. If it’s valid instead, there’s no need to check the long-lived one as well
This allows you to keep a session active for a very long time (the validity of the long-lived token) but only check for its validity on the database every N minutes, depending on the validity of the short-lived token. Every time the short-lived token expires, you can go ahead and re-validate the long-lived one, hitting the database.
Other major companies, such as Facebook, keep track of all of your sessions in order to offer an increased level of security:
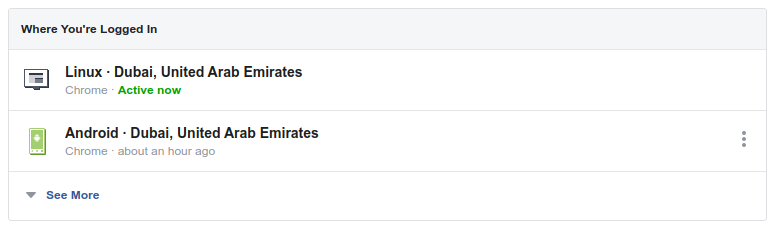
This approach definitly “costs” them more, but I’d argue it’s essential for such a service, where the safety of its user’s information is extremely important. As we stated multiple times before, choose your approach after carefully reviewing your priorities, as well as your goals.
My CDN was compromised!
Often times, web applications serve part of their content through a CDN, typically in the form of static assets like Javascript or CSS files, while the “main” document is rendered by a webserver. This gives developers very limited control over the static assets themselves, as they’re usually uploaded to a 3rd-party CDN (eg. CoudFront, Google Cloud CDN, Akamai).
Now, suppose an attacker gained access to your login credentials on the CDN provider’s portal and uploaded a modified version of your static assets, injecting malicious code. How could you prevent such a risk for your users?
Browser vendors have a solution for you, called sub-resource integrity (abbr. SRI). Long-story short, SRI allows your main application to generate cryptographic hashes of your static files and tell the browser which file is mapped to what hash. When the browser downloads the static asset from the CDN, it will calculate the asset’s hash on-the-fly, and make sure that it matches the one provided in the main document. If the hashes don’t match the browser will simply refuse to execute or render the asset.
This is how you can include an asset with an integrity hash in your document:
1 2 3 4 5 6 | |
The integrity hash can be computed with a simple:
1
| |
A working example can be found at github.com/odino/wasec/tree/master/sub-resource-integrity: after you’ve ran the webserver with a simple node index.js you can visit http://wasec.local:7888 to see SRI in action.
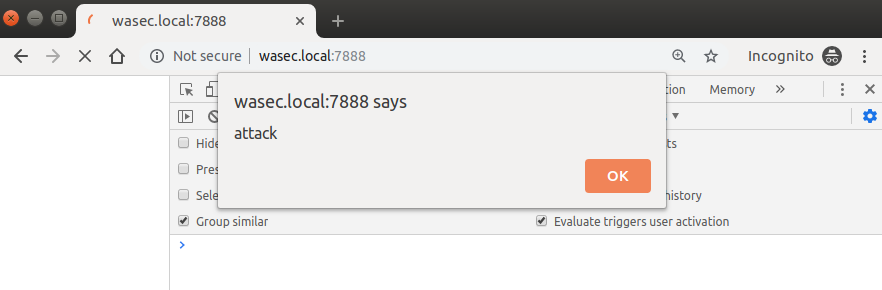
Two scripts are included in the page you’re opening, one that’s legitimate and one that’s supposed to simulate an attacker’s attempt to inject malicious code in one of your assets. As you can see, the attacker’s attempt proceeds without any issue when SRI is turned off:
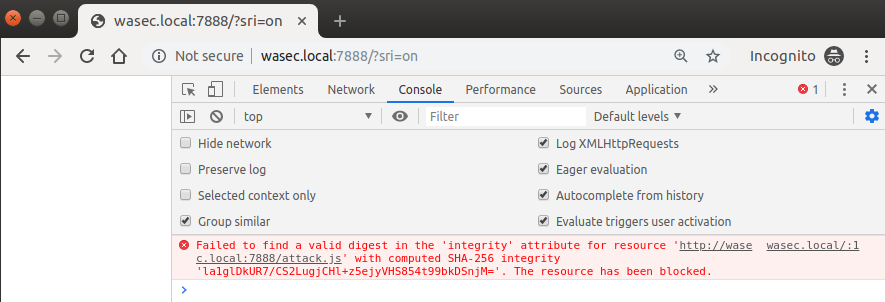
By visiting http://wasec.local:7888/?sri=on we get a completely different outcome, as the browser realizes that there’s a script that doesn’t seem to be genuine, and doesn’t let it execute:
Here is what our HTML looks like when SRI is turned on:
1 2 3 4 5 6 | |
A very clever trick from browser vendors, and your users are secured should anything happen to the files hosted on a separate CDN. Clearly this doesn’t prevent an attacker from attacking your “main” resource (ie. the main HTML document), but it’s an additional layer of security you couldn’t count on until a few years ago.
The slow death of EV certificates
More than once in my career I’ve been asked to provision an EV certificate for web applications I was managing, and every single time I managed my way out of it — not because of lazyness, but rather due to the security implications of these certificates. In short? They don’t have any influence on security, and cost a whole lot of money: let’s try to understand what EV certificates are and why you don’t really need to use one.
Extended Validation certificates (abbr. EV) are a type of SSL certificates that aims to increase the users’ security by performing additional verification before the issuance of the certificate. This additional level of scrutiny would, on paper, allow CAs to prevent bad actors from obtaining SSL certificates to be used for malicious purposes — a truly remarkable feat if it would actually work that way: there were some egregious cases instead, like the one where a researcher named Ian Carrol was able to obtain an EV certificate for an entity named “Stripe, inc” from a CA. Long story short, CAs are not able to guarantee an increased level of security for EV certificates.
If you’re wondering why are EV certificates still a thing to this day, let me give you a quick answer: under the false assumption of “added security”, EV certificates used to have a special UI in browsers, sort of a “vanity” feature CAs would charge exorbitant amount of money for (in some cases more than $1000 for a single-domain EV certificate). This is how an EV certificate would show up in the user’s browser:

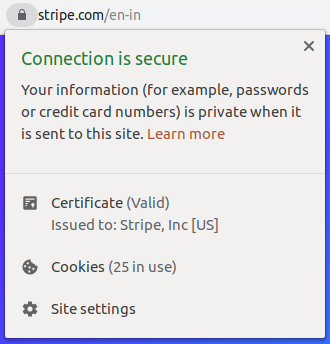
As you can see, there is a “nice” UI pattern here, with the problem being that it is of no use from a security perspective. As soon as research after research started to point out how ineffective EV certificates are, in terms of security, browsers started to adapt, discouraging websites from purchasing EV certificates. This is how the browser bar looks like when you access stripe.com from Chrome 77 onwards:

The additional information (such as the organization’s name) has been moved to the “Page Info” section, which is accessible by clicking on the lock icon on the address bar:
Mozilla has implemented a similar pattern starting with Firefox 70, so it’s safe to safe you shouldn’t bother with EV certificates anymore:
- they do not offer any increased level of security for your users
- they do not get a “preferential” UI at the browser-level, making it a very inefficient expense compared to regular SSL certificates you can obtain (Let’s Encrypt certificates are free, for example)
Troy Hunt summed the EV experience quite well:
EV is now really, really dead. The claims that were made about it have been thoroughly debunked and the entire premise on which it was sold is about to disappear. So what does it mean for people who paid good money for EV certs that now won’t look any different to DV? I know precisely what I’d do if I was sold something that didn’t perform as advertised and became indistinguishable from free alternatives…
Paranoid mode: on
Remember: being paranoid might sometime cause a scoff from one of your colleagues or trigger their eye roll, but don’t let that deter you from doing your job and making sure the right precautions are being taken.
Some users, for example, do not appreciate enforcing 2FA on their account, or might not like to have to CC their manager in an email to get an approval, but your job is to make sure the ship is tight and secure, even if it means having to implement some annoying checks or processes along the way. This doesn’t mean you should ask your colleagues to get a notary public to attest their printed request for a replacement laptop, so always try to be reasonable.
I still remember being locked out of an AWS account (I stupidly let my password expire) and having to ask our Lead System Administrator for a password reset with an email along the lines of “Hi X, I’m locked out of my AWS account, can you reset my password and share a new, temporary one here?”.
The response? A message on WhatsApp:
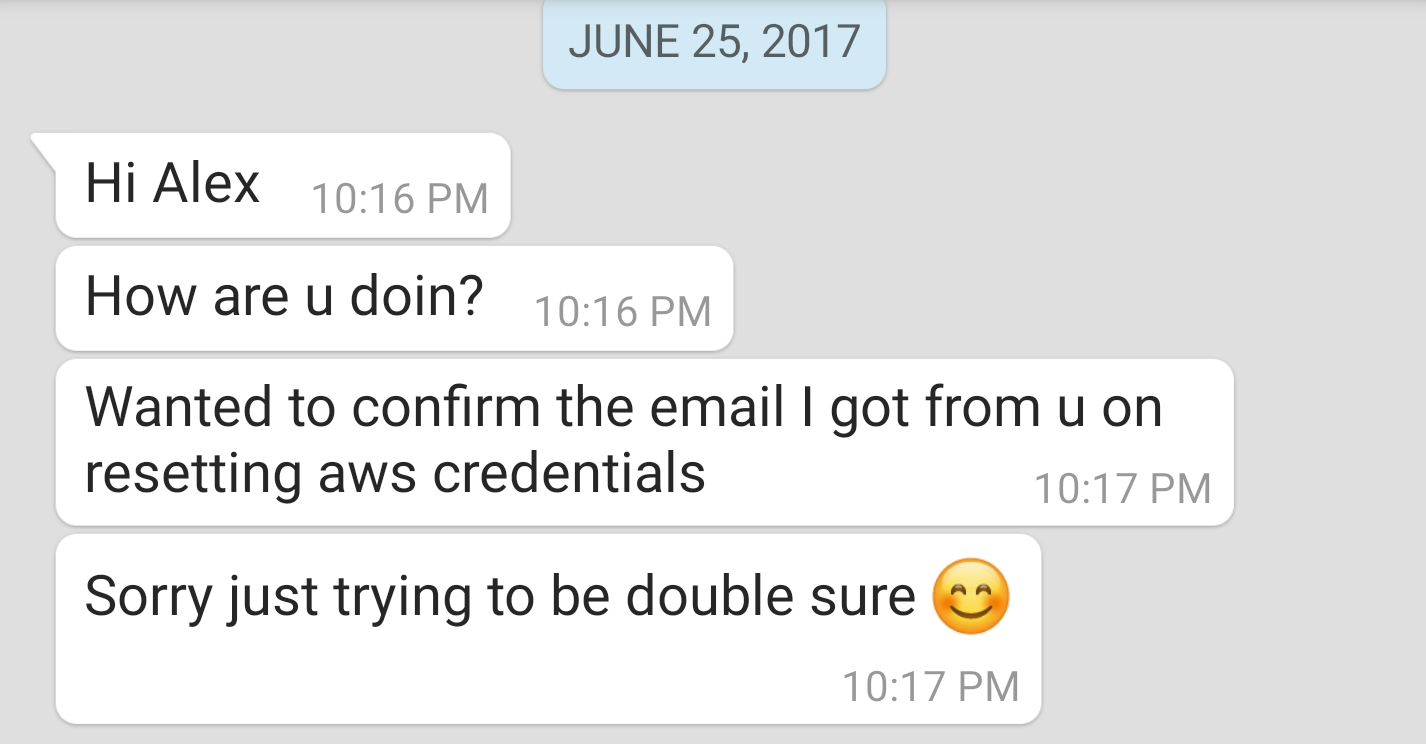
This was the right thing to do, as a person with malicious intentions could have just gotten a hold of my email account and try to steal credentials by posing as me. Again, being paranoid is often times a virtue.
Low-priority and delegated domains
What is Google?
A search engine you might say, but then you’d find yourself thinking about the vast amount of products that they offer and quickly realize Google is a conglomerate that offers a growing number of products, starting with household names such as Maps to little-known services like Keep or Chrome Remote Desktop.
You might be wondering where we’re headed, so let me clarify that right now: the organization you work for probably has more than one service it offers to customers, and those services might not really be related to each other. Some of them, for example, could be low-priority ones the company works on, such as a corporate or engineering blog, or a URL shortener your customers can use alongside other, far bigger services you offer. Often, these servics, sit on a domain such as blog.example.com.
“What’s the harm?”, you say. I would counter that using your main domain to store low-priority services can harm your main business, and you could be in for a lot of trouble. Even though there’s nothing inherently wrong with using subdomains to serve different services, you might want to think about offloading low-priority services to a different domain: the reasoning behind this choice is that, if the service running on the subdomain gets compromised, it will be much harder for attackers to escalate the exploit to your main service(s).
As we’ve seen, cookies are often shared across multiple subdomains (by setting the domain attribute to something such as *.example.com, .example.com or simply example.com), so a scenario could play out where you install a popular blogging software such as WordPress on engineering-blog.example.com and run with it for a few months, forgetting to upgrade the software and install security patches as they get published. Later, an XSS in the blogging platform allows an attacker to dump all cookies present on your blog somewhere in his control, meaning that users who are logged onto your main service (example.com) who visit your engineering blog could have their credentials stolen. If you had kept the engineering blog on a separate domain, such as engineering-blog.example.io, that would not have been possible.
In a similar fashion, you might sometime need to delegate domain to external entities, such as email providers — this is a crucial step as it allows them to do their job properly. Sometimes, though, these providers might have security flaws on their interfaces as well, meaning that your users, on your domains, are going to be at risk. Evaluate if you could move these providers to a separate domain, as it could be helpful from a security perspective. Assess risks and goals and make a decision accordingly: as always, there’s no silver bullet.
OWASP
Truth to be told, I would strongly recommend you to visit the OWASP website and find out what they have to say:
- OWASP Cheat Sheet Series (https://cheatsheetseries.owasp.org): a collection of brief, practical information. You can find inspiring articles such as how to harden Docker containers or in what form should passwords be stored. It is a very technical and comprehensive list of guides that inspired the practical approach used in this chapter of WASEC
- OWASP Developer Guide (https://github.com/OWASP/DevGuide): a guide on how to build secure applications. It is slowly being rewritten (the original version was pubished in 2005) but most of the content is still very useful
- OWASP Testing Guide (https://www.owasp.org/index.php/OWASP_Testing_Guide_v4_Table_of_Contents): on how to test for security holes
These are 3 very informative guides that should help you infusing resistance against attacks across your architecture, so I’d strongly suggest going through them at som point in time. The Cheat Sheet Series, in particular, is extremely recommended.
Hold the door
Now that we went through a few common scenarios you might be faced with in your career, it’s time to look at the type of attack that has garnered the most attention in recent years due to the widespread adoption of both cloud computing and IoT devices, allowing attackers to create armies of loyal soldiers ready to wreck havoc with our networks.
They are distributed, they are many, they grow in intensity each and every year and represent a constant treat to public-facing companies on the internet: it’s time to look a DDOS attacks.