I recently gave another read at my original post “REST better: HTTP cache” and I felt compelled to write a more in-depth dive into the subject, especially since it’s one of the most popular topics in this blog; at the same time, with the advent of new technologies such as sevice workers, people jumped into the bandwagon of offline applications without, in my opinion, understanding that the HTTP cache provides some basic but extremely interesting features for offline experiences — thus, I want to shed some light on one of the most ingenious sections of the HTTP protocol.
What is the HTTP cache?
First of all, let’s start by dividing HTTP into 2 entities:
- the spec1, which highlights how messages can be exchanged between clients and servers
- the implementation (for example, Google Chrome is an HTTP client, Nginx implements an HTTP server and so on)
So, for example, with HTTP/2 we have seen a revamped implementation, one that brings TSL by default, that turned plaintext messages (the way messages were exchanged in HTTP/1) into binary, along with the introduction of multiplexing (in short: one connection can channel multiple requests and responses) and the likes — HTTP/2 was a massive upgrade to HTTP and is making the web a much safer, faster place. At the same time, the spec itself didn’t change as much, as the semantics of the protocol have been widely unaffected by HTTP/2.
HTTP caching falls under the HTTP spec, as it’s simply a chapter that defines how messages can be cached by both clients & servers: the current version of the HTTP caching spec is RFC7234, so you can always head there and have a look by yourself.
The goal of the HTTP caching spec is, in short, to:
[…] significantly improve performance by reusing a prior response message to satisfy a current request.
or, as some smart guy once said:
[…] never generate the same response twice
As you might have guessed, the HTTP cache is there so that we hit servers as less as possible: if we can re-use an existing response, why sending a request to the origin server? The request needs to cross the network (slow, and TCP is a “heavy” protocol), hit the origin server (which could do better without the additional load) and come back to the client. No bueno: if we can avoid all of that we, first of all, take a huge burden off our servers and, second, make the web faster, as clients don’t need to travel through the network to get the information they need.
A side effect of HTTP caching is the fact that it makes the web inconsistent: a resource might have changed and, by serving a cached, stale version of it we don’t feed the clients the latest version: this is, generally, an acceptable compromise we, as developers, make in order to scale better. In addition, these inconsistencies can be avoided by tweaking the cacheability of our responses, and we will look at how to do that in the next paragraphs.
In defining mechanisms to implement this kind of performance optimizations, the W3C working group split caching into 2 main variants: expiration, which is simpler but very high-level, and validation, which gives you more granularity.
Let’s look at expiration first, as it’s the way we use HTTP caching on a daily basis.
Expiration
This is the sort of caching you’re used to see every day, which allows you to specify TTLs (time to live) for static assets like JS, CSS & the likes: we know those assets are cacheable for a long time, so we specify an expiration date on those resources.
As I mentioned, expiration is generally used for static assets, but can be used
for any kind of resource (ie. GET /news/1), so don’t just think caching is for
content that never changes (such as a minified JS file).
How can we implement expiration though? Through 2 very simple HTTP headers.
Expires
The Expires HTTP header allows us to specify a future date that defines until
when a resource should be cacheable:
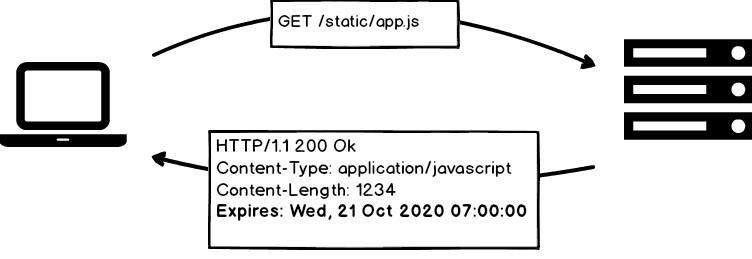
If the client needs to fetch the same resources later on, it will first figure out if it has expired and, if not, use the local copy stored in the cache, without hitting the origin server. An example implementation might look like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
This is a very simplistic implementation, but should give you an idea of the
process an HTTP intermediary (a browser, a proxy, etc) goes through when
implementing basic HTTP cache through the Expires header.
Cache-Control
If we want to get a bit fancier, we can use the Cache-Control header, which allows
us more control over how a response should be cached; for example, here’s an HTTP
response using Cache-Control:
1 2 3 4 5 6 | |
Wow, that’s a lot of stuff to process, so let’s break it down:
Cache-Controlallows you to embed multiple caching directives into one header- directives are comma separated
- in most cases, directives are parsed as key-value pairs (ie.
key=val) — some of them, though, require no value (ie.no-transform) - they control different aspects of the cacheability of a resource
So what directives can we use in here?
public, which means that the resource can be cached by any cache (read on)private, which means that the resource can only be cached if the cache is not shared. A browser is a private cache, while a proxy is a shared cache, as it channels requests and responses from and to multiple clients. For example, the resource atGET /customers/mecould possibly be cached by private caches (my own browser), but not by shared caches, as they would end up showing my user profile information to other usersmax-age, the TTL, in seconds, of the resource.max-age=60means it is cacheable for 1 minutes-maxage, which is exactly likemax-agebut applies to shared caches only (hence thes-prefix)must-revalidate, which indicates that once the resource is stale, the cache should not serve it without first re-validating it with the serverproxy-revalidate, same asmust-revalidatebut for shared cachesno-cachetells the cache it always needs to revalidate the resource with the origin serverno-store, which means you should not cache the resource at allno-transformsays the intermediary should not toy around with the response payload at all (I’ve never seen intermediaries doing so, so I’m assuming this is how most softwares like browsers or gateway caches behave by default)
Most people think that the Cache-Control is a response header, whereas it can be included in HTTP requests as well — and the directives you can use are slightly different:
max-age: the client will discard responses with anAgeheader older than the value of this directivemax-stale: here the client advertises that if the server is willing to serve a stale response (to avoid hitting the DB, for example) it can do so as long as the response is not older than the value of the directive (ie.max-stale=60). This is a very clever mechanism to allow servers to do less work!mix-fresh: the opposite ofmax-stale. The client will accept cached responses only if they’re fresher than this valueno-cache: don’t even try… :)no-transform: same meaning that it would have in an HTTP responseonly-if-cached: the client will only accept cached responses
Stale-* directives
An ingenious trick, the stale-while-revalidate and stale-if-error cache-control
directives are worth a mention on their own, as what they let you achieve is pretty
interesting:
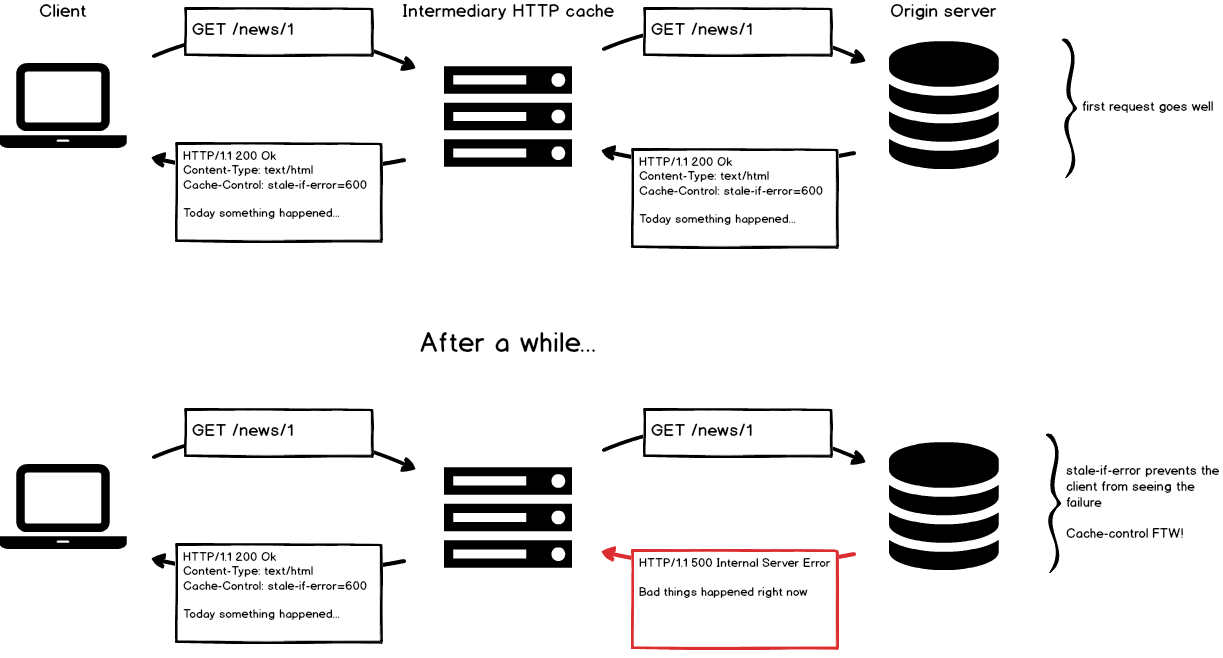
stale-if-errortells the cache that it can serve a cached response if, by any chance, it encounters an error when fetching a fresh response from the origin server. In other words, this means that an HTTP cache can be smart enough to serve cached content when you server starts returning 500 errors — talk about fault tolerance!
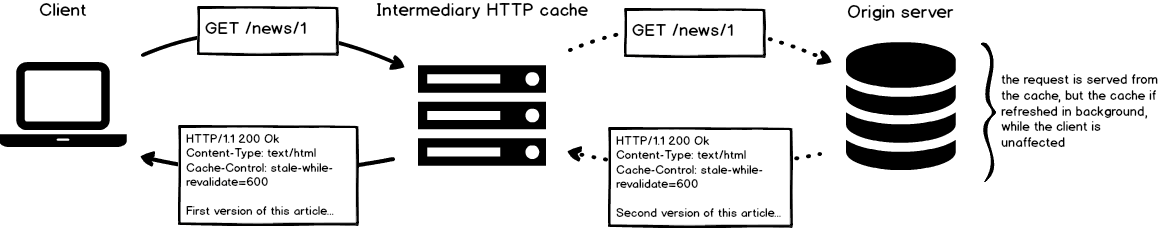
stale-while-revalidatelets you serve cached content while refreshing the cache instead. This is fairly interesting as, if 100 clients are accessing your cache at T0, you can serve them a cached resource at T1 (even if it’s stale), while revalidating the cache in background. If a client then requests the same resource at T2, he will receive the version that’s been revalidated from the origin server
Funny enough, Chrome has been considering implementing this directive for quite some time, and last I heard it was still just under consideration, though it looks like it might never going to make it to Chrome Stable.
Pragma: an obsolete header you’ll still see around
Cache-Control was introduced in HTTP/1.1, meaning there had to be some way to
control caches in the olden HTTP/1.0 days — that would be
the Pragma header.
Pragma doesn’t let you do much, as you can just tell caches not to cache through
Pragma: no-cache — nothing too complicated here.
What’s interesting, though, is that a few HTTP clients will still consider responses
cacheable if they don’t see a no-cache in the Pragma, and so the best practice
to avoid caching has been to send both Cache-Control and Pragma:
1 2 3 | |
At the same time, a peculiar use of Pragma is by telling HTTP/1.0 caches not to
cache (via Pragma) while allowing HTTP/1.1 caches to do so (via Cache-Control):
1 2 3 | |
Enough with expiration: it’s now time to move on to validation, a more expensive but granular way to implement HTTP caching.
Validation
Expiration provides a very interesting way to keep clients off the server, at the cost of serving stale content more often than we’d might like: in cases when that’s not an acceptable compromise you can use validation, as it ensures clients will always be able to receive the latest, most fresh version of a resource.
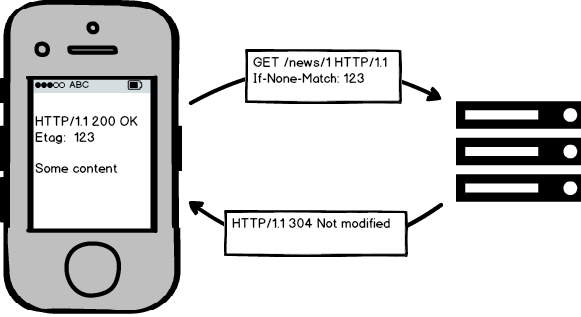
At its core, validation works in a very simple manner: when you request a resource,
the server assigns a “tag” to it (let’s say v1) and the next time you request the
same resource you include the tag in your request; the server, at this point, can
quickly check if the resource has changed: if so, it returns the new version, else
it tells you to use the cached version you should have with you.
In HTTP words this is how it basically works:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
As you see, returning a 304 Not Modified is cheaper as it doesn’t contain as many
information as the “real” resource: less packets traveling through the network, thus
a faster response.
At the same time, calculating an Etag (the HTTP header used to tag resources) is
generally cheaper than rendering your resource again — let’s look at some pseudo-code
to understand what we’re talking about:
1 2 3 4 5 6 7 8 9 10 | |
We have saved the server some extra work by not rendering the news template all over again: this might feel like a small saving, but put it in the context of thousands of requests every day and you see where we’re going.
Looking back at our second request:
1 2 | |
you might be wondering what’s that If-None-Match, so let me break the whole
process down for you:
- client requests a resource
- server returns it and tags it with the
Etagheader - client requests the same resource again, and tells the server to return it only if the resource’s etag doesnt match the one we’re sending (that’s why the header is called
If-None-Match)
A request that contains the If-None-Match header is called a “conditional request”:
it’s expected to fetch a resource only if the condition it is sending
won’t be satisfied (the condition is that the client’s etag matches the server’s).
Conditional requests and validation can be implemented with etags as well as dates:
if you’re more comfortable using the latter (think of an updated_at column in the DB)
you can replace Etag with Last-Modified and If-None-Match with If-Modified-Since:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Again, the spec is very simple and doesn’t get too fancy, yet it’s powerful enough
to let you save so much time and data by returning 304 rather than “full” responses —
that’s why I like the HTTP caching spec: it’s so clever and simple!
Who can cache my responses?
HTTP is a layered protocol, meaning there can be countless intermediaries between the client and the server — a picture is worth a thousand words:
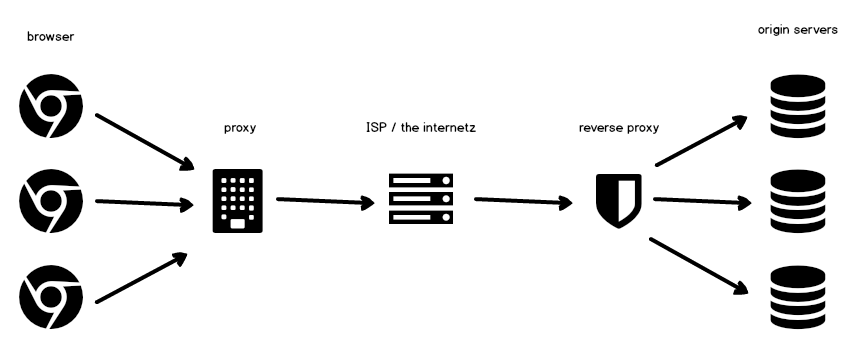
So, who are all these guys that can cache resources all along the way?
- nothing to explain in terms of browsers, as we’re all familiar with them.
Worth to note that, when you use
curlfrom your command-line, that’s your browser - proxies, instead, are generally installed between the client and the internet, and they provide a shield between the two. Proxies are shared caches as, for example, you could install them at your company so that multiple browsers use the same proxy — that way, if I request a cacheable resource and one of my co-workers requests the same, he will be served the cached response I generated, by the proxy
- ISPs / the internet: well, that’s the backbone of your internet connection, and they could implement caching on their own
- proxies installed on the server-side are called reverse proxies instead, as their job is to shield multiple servers from requests. Reverse proxies are also called “HTTP accelerators”, as their main job is to avoid requests from hitting the origin servers. Varnish is one of the most popular reverse proxies out there
- last but not least you’ve got your origin servers, where your applications run. They can implement HTTP caching on their own, even though it’s generally preferred to have a dedicated reverse proxy to offload origins
Warning: when things don’t go as planned…
An interesting header is Warning, as it’s used to signal that something went wrong
when fetching the response from the upstream, something that’s hard to infer from the HTTP status code
alone: for example, when the cache knows that the response being served is stale, it
could include a Warning: 110 - "Response is Stale" to inform the client that the response
he’s receiving isn’t fresh at all — that, for example, could happen when stale-while-revalidate
or stale-if-error kick in:
1 2 3 4 5 | |
A note on Service Workers
Here comes the fun part: if you’re a web developer chances are you’ve heard you
should implement service workers in order to efficiently serve cached content, and
that’s quite misleading — to be clear, you can have offline apps working
without service workers, as when you tap on a link and that renders a response with,
say, Cache-Control: max-age=3600, you can still open that page for another hour,
without an internet connection.
Service workers give you a great deal of control on the network stack, allowing you to intercept HTTP requests being made, hijack them and, as many advise, cache them on-the-fly — but I’d honestly avoid doing so as you can achieve the exact same thing with the HTTP cache and way less code.
Let me rephrase it: if all you need is caching static assets or do expiration-based caching, do not use service workers as the HTTP cache gets the same job done. If you need some special functionality that is not included in the caching spec, then use a worker, but I’d be very surprised to hear you needed to: the contexts where you would be able to take advantage of the SW’s capabilities are quite advanced, and I could argue HTTP caching would anyhow get you ~95% there even in those cases.
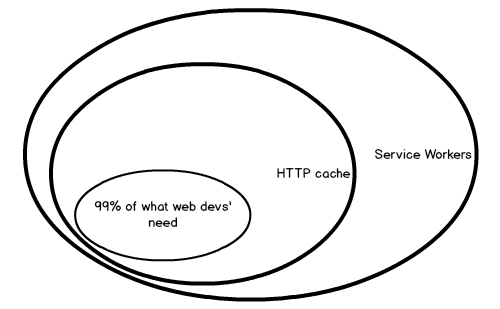
Service workers are great because they let us implement functionalities we traditionally never had on the web (think of push notifications, add to homescreen, background sync and the likes) but, for stuff that’s been there, I would advise to stick to the basics.
Let’s have a look at an example code from a service worker that implements its own caching — as you see not most straightforward code you’ll bump into:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
As Jake Archibald, developer advocate at Google, puts it:
You can hack around poor caching in your service worker, but you’re way better off fixing the root of the problem. Getting your [HTTP] caching right makes things easier in service worker land, but also benefits browsers that don’t support service worker (Safari, IE/Edge), and lets you get the most out of your CDN.
Ditto.
Conclusion
Caching in HTTP has been here for almost 2 decades, it’s a battle-tested part of the protocol and allows you to efficiently trade freshness with scale (emphasis on efficiently): there’s no reason to implement our own application-level caches when the protocol we use to exchange messages allows you to do the same, for free, by just jamming a bunch of headers in your responses.
HTTP caching is truly the hidden gem of the protocol, and I wish more people would be aware of the inner workings of the spec — to me it is a great example of achieving great results without compromising on complexity, and this is the kind of design we should aim towards when building software.
In short: the HTTP cache is great. Be like the HTTP cache.
Further readings
If you enjoyed this article I would suggest you to read further stuff on the HTTP cache:
- the complete HTTP caching spec
- I have a few articles on this very same blog
- Mark Nottingham’s blog (Mark is known for his contribution to the HTTP protocol, web caching and for being the “chairman” of HTTP/2)
- Ryan Tomayko is a very smart guy who spoke about HTTP caching in the past. He turns whatever he touches into gold, so follow him ;–)
- Subbu Allamaraju is a well-known member of the REST community and has written about HTTP caching in the past
See you next time!
- Worth to note that RFC2616 has been superseded by a few updates (RFCs 7230, 7231, 7232, 7233, 7234, 7235, which update part of the original spec) ↩