I am writing this post in the middle of revamping Namshi’s architecture with AngularJS, reverse proxies, SPDY and HTTP APIs, because I strongly believe in the future of these technologies and that they are the de-facto cutting-edge solution for most of the antipatterns that we’ve seen so far: monolithic applications, unscalable frontends, limited protocols.

So why would I rant about it? Well, this is not a real rant but it’s more of a retrospective on the gotchas that we faced over the past months: I do really enjoy all of this techs, but also recognize that most of them are at a very early stage and have their pitfalls when it comes to develop real-world, scalable architectures.
The boring part’s over, let’s get into the real mess ;–)
Reducing redirects?
Suppose that you have a frontend, maybe built with AngularJS,
that proxies all the requests to an API, so if you request
example.org/about, your frontend actually gets the content
from api.example.org/about.
One of the things that you can start optimizing are the
round trips between the client and the server (very important
for mobile connections): for example,
instead of sending simple redirects from your API to the
frontend, you can return a 30X and include the actual body
in the response; in this way, the client can:
- read the body of the response and work with it (output or whatever)
- update the browser URL according to the
Locationheader provided in the response with the browsers’ history API
NOT. SO. FAST.
Turns out that modern browsers intercept redirects and make an
additional HTTP request to the Location provided by the response.
This behavior is pretty useful in 98% of your use-cases, as you dont have to take care of handling AJAX redirects on your own and you have a pretty simple solution, using a custom HTTP status code, like 278, for the remaining 2% of scenarios.
NOT. SO. FAST. 2.
Of course, the magnificent Android native browser
will mess this up, thinking that 278 is an error code: so if, for
your HTTP request, you have a callback in case of success and
one in case of an error, the latter will be triggered.
How to deal with this?
Well, we decided to return straight 200 Ok codes and include
2 custom headers, X-Location and X-Status-Code, that our
clients will parse to find out if they need to update the
browser’s URL.
In pseudo-code:
1 2 3 4 5 | |
In any case, with the growing amount of mobile clients, I think
it might make sense to start thinking of an appropriate process
to handle redirects, within the HTTP protocol, so that browsers
can just follow the spec: in my opinion we could use something
like 308 Transparent redirect for this.
Reverse proxies and HTTP cache

Two of the most important directives
that you can use while taking advantage of the HTTP cache
are stale-while-revalidate and stale-if-error:
the former lets you return stale responses
while you revalidate the cache while the latter lets you serve
cached responses if your backend is down (50X errors).
Of course, you will need a reverse proxy in front
of your webserver in order to really take advantage of
these directives: Squid natively implements
both of them but, in our case, it was too much of a hassle to setup,
as it’s bloated compared to its cousin Varnish,
which doesn’t natively implement stale-* directives instead.
Setting up Varnish to support those 2 directives it’s a matter of a few tries anyhow, as you can mimic the (almost) same behaviors with Varnish’s grace and saint modes.
Android’s native browser

Android, oh Android!
As we already saw, its native browser doesn’t let you play around with unconventional HTTP status codes1 and, on top of that, it breaks the HTTP cache.
If you have a cacheable resource that you retrieve via AJAX,
the first request to retrieve will work, but as soon as you reload
the page and retrieve it a second time, the browser messes things up,
things that the request returned an invalid HTTP status code (0)
and aborts the process.
And yes, it’s a known bug.
Performances on old devices
And when I say old I mean stuff like the Galaxy S2 or S3, which are not that old to be honest.
Performances are anyhow a huge concern when you start moving the logic into the clients, as resources might be very limited: let’s not forget that the first generation of Galaxy – or even the iPhone 4 – were shipped out with just 512mb of RAM; think of a JS-heavy app, which sucks up to 40/50mb of RAM: how would that perform on those devices?
Let me tell you that: it’d be very slow, and would even feel slower when CPUs comes into the mix as – we’ve witnessed it – to build DOM elements2 it could take up to 4s. Of course, you can optimize it, but a brand new smartphone wouldn’t let you feel such lag: truth is that when you decide to go for a JS app you need to take into account the time spent in optimizations for old devices, as you’ll surely need to invest on it.
What a hard time debugging browser events
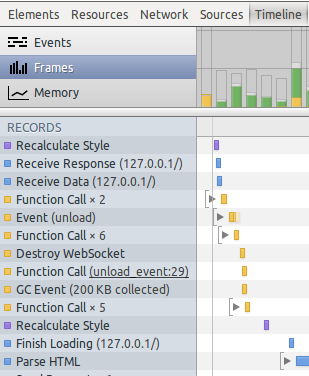
If you’ve ever dug deep into optimizing browser events (HTML parsing, repainting and so on) you probably know what I’m talking about: the devtools are still at an early stage and it becomes really tricky to be able to nail issues down or at least to efficiently reverse engineer them; even though you have a breakdown of every browser event it’s actually pretty difficult to trace events back to their “cause”3.
Chrome provides profiles and the timeline which are very useful resources, but you can’t really inspect that much as at a certain point you’ll end up with a lot of events like HTML parsing or Function call and only God knows where they exactly came from.
Persistent sessions and credentials

Authenticating users might be tricky for frontend apps: you don’t have the good old (and heavy) PHP sessions that you can just fill up on you server, but you – at least initially – can try to persist sessions on cookies or localStorage.
But even before thinking of storing sessions you have to deal with authenticating each of your user from the app: granted that the HTTP basic auth is not good as it’s flawed and that the digest auth might be too simple, you should start looking at alternative methods to authenticate and authorize your users, preferrably using tokens.
As you probably figured out, there is no real standard mechanism of doing this, as some providers rely on oAuth (both 2-* and 3-legged) and some on OpenID. Even Mozilla, a while ago, came out with its own protocol, Persona, to solve this problem.
We actually found out another “protocol” to store and transmit credentials through HTTP APIs, the Javascript Object Signing and Encryption specification (JOSE).
A note on AngularJS and the Grunt ecosystem
A glimpse of our package.json:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
As you see, the bower/node/grunt/angular ecosystem is still very young and, from certain points of view, very immature (for example, SSL support in Grunt was added just 2 months ago).
So if you want to use these kind of technologies you must accept that, sometimes,
doing an npm install might break something, or that you will need to keep your deps
updated to the latest releases: it’s all about go big or go home.
Internet Explorer. As always.

Eheh, there could not be a post about web gotchas without mentioning IE:
the lack of support for CORS
in IE8 and IE9 is actually a real kicker for
efficiently implementing frontend apps that rely on a remote API
(example.org –> api.example.org), since CORS considers as cross-domain
even a request on a subdomain4.
And no, there is no native escape strategy for this: you must extend the XHR in order to make it capable of doing cross-domain communication through Iframes, a strategy that even Google and Facebook have implemented in the past; luckily there is some stuff already written for us, so we can use the good xDomain and include it with the IE conditional comments.
But then, you would think, why not using xDomain for everything, and simply drop CORS?
Well, there are a few things to consider:
- even though Google and Facebook are known to be using some trick like xDomain, it’s pretty strange that they havent released anything yet (might be that they don’t consider it a long-term option)
- the native Android browser was known to have issues with this library
- CORS is a growing standard that has been widely adopted by the community
- the code looks kind of cryptic
All in all, we didnt feel like using xDomain for everything, as we are just using it for IE8/95: Jaime did a great job implementing it but I personally feel that it might be too much to just blindly rely on it for cross-domain communications.
CORS and HTTP headers
Deciding to go with CORS it’s just half of it, as the other half consists
into actually implementing CORS on both your clients and servers (APIs): it’s
worth mentioning that the specification is really strict when it comes to
send and manipulate custom HTTP headers (like the X-Location that we
saw at the beginning of this post).
If you wanna send a custom header you will need to specify it in the
Access-Control-Request-Headers header:
1
| |
and if you want your clients to be able to access some of the response’s headers you will need to declare them as “accessible”:
1
| |
How to do RUM?
Another good question (and I don’t have an answer so far) is how to measure performances as felt by the end-user (Real User Monitoring), since AngularJS loads once and then never triggers server-side measurable events other than HTTP requests to your APIs: the API’s response times cannot be taken into account as you wouldn’t measure the performance perceived by the end user – remember, JS frameworks add HTML parsing, data-binding and so on on top of the cake.
We still have to figure out how we will implement RUM in our apps, if you have any suggestion it would be highly appreciated!
All in all…
Developing on the frontend is an amazing experience that has some drawbacks, like on any platform: beware of the specs (like CORS) and gotchas (IE, Android’s native browser) and you will enjoy it to the max!
P.S. Thanks to HZ and AdamQuadmon for passively contributing to this post, sharing with me and the rest of our team this amazing and tortuous experience