HTTP has a widely-ignored cache specification which helps us implementing fast, scaleable and fault-tolerant services.
What does this have in common with REST?
Is that only because HTTP is a REST-loving protocol?
No.
Cache is the third constraint of the REST architectural style, and there’s a reason behind it:
The advantage of adding cache constraints is that they have the potential to partially or completely eliminate some interactions, improving efficiency, scalability, and user-perceived performance by reducing the average latency of a series of interactions.
Why caching?
If you aren’t convinced by Fielding’s words, here are other explanations:
- improve speed, because we want to deliver fast content to our consumer
- fault tolerance, because we want our service to deliver content also when it encounters internal failures
- scalability, because the WWW scales to bilions of consumers through hypermedia documents and we just want to do the same thing
- reduce server load, because we don’t want our servers to compute without the need of it
Types of cache
There are a few types of caches, but not all of them fit well in a qualitative architecture:
Local cache
It’s a cache a single consumer implements.
When you surf an http-cache-loving service with the browser cache activated, you should be able to experience significant speed improvements when requesting the same page more than once: that’s because your browser, according to the response’s caching headers, has a local copy of the response on your machine, and when you request the page the second time it uses that local copy instead of making a real request over the network.
Needless to say, improvements on local caches can be obtained by using an in-memory caching strategy rather that a disk-persisting one.
Proxy cache
You may confuse proxy cache with gateway one: I’m gonna talk about the latter in a few lines.
Proxy caches are shared caches that, for instance, your company can install in front of your firewall in order to store many resources, from many origin servers, on behalf of every agent in your company.
The difference between local and proxy cache is that the former can’t serve more than one agent, so 2 identical requests from 2 consumers behind the same network effectively hit the origin server twice: again, needless to say, proxy caches serve cached responses slower than local ones.
Application cache
Oh, WTF.
This kind of caches are evil: we spent the last 15 years of web development on developing frameworks with their own super-cocky caching layer.
Although they might help reducing the web’s inconsistency, they’re a needless way to waste effort: the HTTP specification and the software implementing it ( some web frameworks, reverse proxies and browsers ) are the standard tools we should use in order to deliver cached content.
If we aren’t satisfied by this tools, we can think about implementing a caching layer over our software, but only in this case.
You are probably wondering why I hate application caches, and the answer it’s easy: you don’t need to mantain a browser, nor a proxy, nor a reverse one; that means that without LoCs you have an efficient caching layer upon your architecture, for free. Thanks, HTTP.
Another reason I hate application cache is because it couples a peculiarity of your architecture ( being cacheable ) with the application at the base of it: that means that changing the implementation will change your architecture capabilities.
Are you OK with that? Well, I’m not: loose over strong coupling, one of our primary goals.
Gateway cache
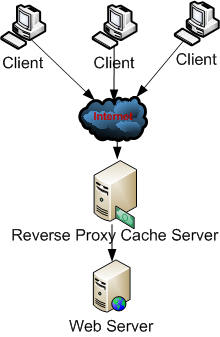
A gateway cache is a cache served by a proxy installed on the server side, called reverse proxy.
It’s different from the proxy cache, in which the proxy stands into the client side: the advantage of implementing a gateway cache is that you can share the cache generated by a client with any other client of the planet doing the same request.
A few words on WWW’s inconsistency
Cache introduces inconsistency, which is the situation that occurs when a resource served to a consumer is different from the one actually held by the server.
Crap, you say, and that’s true, but is also the reason behind a system serving bilions of users with an unimaginable amount of data, the WWW.
You must be ok with this assumption: if you need consistency we will see later how to couple caching with high consistency ( keep in mind the word ESI ).
Caching headers
There are a few HTTP headers you can use to specify caching rules for your resources: here’s a recap about them.
Expires
Used in HTTP responses, the Expires header tells the client when the resource is going to expire.
Usually, this headers has a date value that specifies from when the resource will be considered stale ( possibly out-of-date ), and so it needs to be revalidated.
In order to avoid caching of the response, this header can contain other values, like:
1
| |
or a date that equals the one in the Date header.
When you want to mark the resource cacheable for long times, you can specify a date up to one year in the future.
The “one year” time is a constraint, as the HTTP spec says:
To mark a response as “never expires,” an origin server sends an Expires date approximately one year from the time the response is sent.
HTTP/1.1 servers SHOULD NOT send Expires dates more than one year in the future.
Cache-Control
CC is a powerful header to manage your caching directives and strategies: is a way of combining different directives about the response’s cache.
The cool thing about CC is that it can be also used in requests, so, for example, if your consumer wants to be sure that the data he is receiving are consistent, he can specify an header like the following:
1
| |
which basically tells all the caching layers to revalidate the response with the origin server.
Etag
The etag is a unique identifier for your response: it is used on conditional requests, usually when a clients GETs a resource he also has in cache, sending to the origin server this identifier ( in the If-None-Match header in this case ).
Last-Modified
If Date is the header which tells when the resource has been firstly generated, Last-Modified tells us when it has been… ..well, you guessed it.
More about the Cache-Control
As I said, the CC header combines different directives for specifying a caching strategy, that I briefly explain now.
If you want to specify how long should the response considered valid you use the max-age directive, available for local caches.
The corrisponding for shared caches ( proxies ) is s-maxage: the value of both is expressed in seconds.
If you want to make the response cacheable by both local and shared caches you declare it as public, while if you don’t want to make it cacheable by proxies you should declare it private.
Yes, private doesn’t mean not cacheable: that is achieved by using the no-store directive.
A weird story short, I tend to avoid the no-cache instruction because it’s interpreted in different ways by different caches.
If you want to always revalidate your cached copy you should use must-revalidate for local caches, proxy-revalidate for proxy caches: that’s useful when you have frequently updates on a resource and its etag is cheap to generate, so you spend some computation for comparing the etag with the If-None-Match header and telling the client the response has, or hasn’t, been modified.
A smart instruction, for requests, is the only-if-cached one, when, usually, you deal with slow connectivity:
In some cases, such as times of extremely poor network connectivity, a client may want a cache to return only those responses that it currently has stored, and not to reload or revalidate with the origin server.
To do this, the client may include the only-if-cached directive in a request. If it receives this directive, a cache SHOULD either respond using a cached entry that is consistent with the other constraints of the request, or respond with a 504 (Gateway Timeout) status.
However, if a group of caches is being operated as a unified system with good internal connectivity, such a request MAY be forwarded within that group of caches.
stale-while-revalidate has a value, expressed in seconds, which tells that the cache should release a stale response ( out-of-date ) if the request has come during the specified ( as I said, in seconds ) interval, while stale-if-error has an identical behaviour but it deals with errors contanting the origin server: this directives spread availability over consistency.
Theory is always annoying, so let’s see them in practice.
1
| |
A response with the above CC means that the response:
- is cacheable by local and shared caches
- is cacheable for 10 minutes for local caches
- is cacheable for 1 hour for shared caches
while
1
| |
tells that the response is not cacheable at all.
Talking about availability over consistency, the following
1
| |
is really interesting; it basically says that the response:
- is cacheable by local and shared caches
- if it has expired in less that a minute, the cached copy can be released while persisting the original request to the origin server
- if the request encounters an error and the cached copy has expired in less than 2 hours, the cached copy can be released to the client
Caching strategies
There are only two hard things in Computer Science: cache invalidation and naming things.
dealing with cache consistency should be pretty hard.
You have to 2 ways to improve data’s consistency: cache validation and expiration: only if you implement a mix between validation ( which basically asks you to specify the Etag and Last-Modified headers ) and expiration ( with the Expires header or some Cache-Control directives ) you’re going to increase consistency between cached content and actual data.
Edge Side Includes
ESI, or edge side includes, is a specification introduced by Akamai and Oracle in 2001, which tries to solve the problem of composite webpages.
What is a composite? It is a resource which is composed by the aggregation of N resources, through server side includes ( not SSI ).
The typical ESI tag looks like the following one:
1
| |
and basically tells a proxy that, before releasing a response it should make an HTTP request to the specified src and substitute the esi tag with the response.
ESI helps you having a working and effective gateway cache, because it lets you share a cached resource not only between different clients, but also between different requests.
Granularity FTW.
Another advatage, ESI improves response’s consistency, because it lets you specify caching strategies for single resources that compose another one that you may declare not cacheable: the requested resource isn’t cacheable, but some of the data it contains can be retrieved from the cache.
Needless to say, proxies understanding ESI tags are always put in front of our architecture, on the server side.
Pushing ESI to the next level
The next step in improving the web cache is to move ESI capable proxies to the clients’ side: that would mean that a browser cache or a proxy cache would be able to receive responses with ESI tags and process it.
This would dramatically improve consistency and performances, because we would push cached copies more near to the client, but specifying different TTL ( time to live ) for the response fragments.
There’s only a minor problem: actually, proxy and local caches don’t understand very well ESI tags; for instance, any browser isn’t able to process an ESI tag.
But the biggest problem is that there’s no standard media type which embeds ESI tags in the response, so we would basically send our response, embedding ESI tags, with a custom and widely-unknown media format.
At the Symfony Live conference I talked with Symfony creator, Fabien Potencier, on the possibility of writing a media format for web responses which need to embed ESI tags: my goal is to start to define a standard for this kind of technology.
Missing a standardized format is evil: you are basically ignoring the self descriptiveness constraint of REST, making your architecture hard to consume, discover and mantain. And since self descriptiveness is one of the main actors behind REST’s WSDL ( yes, REST has WSDL, composed by self-descriptiveness, hypermedia formats, media types and DAP1 ), you’re missing a huge part of the service.
People started to like HTTP cache
[The goal is to] never generate the same response twice.
People, get over application cache and re-inventing the wheel: popular tools like Ruby’s Rack ( well, that’s because of the great mind of Ryan Tomayko ) and PHP’s Symfony2 RAD framework are abandoning application caches in favour of the HTTP caching mechanism.
Resources
You should really read Subbu Allamaraju’s articles about HTTP caching.
REST in practice has a cool chapter dealing with scaling through HTTP caching.
And remember:
Make a reasonable guess. Whenever caching is involved, there is a possibility that the content that the end user is receiving is stale. Is this acceptable or not? It depends.
- Domain Application Protocols ↩