- The strange case of OrientDB and graph databases
- An overview of OrienDB’s capabilities
- Going beyond RDBMS
- Just like any other NoSQL database?
This post is part of the ”OrientDB 101” series, derived from a previous work started in 2013/2014: some information might be outdated, but the core of this series should still be intact.
Here is a list of all the articles in this series:
We’ve recently been looking at some of the features of OrientDB, but what about understanding why there has been so much spark in the NoSQL ecosystem over the past 5 years?
Data structures
When comparing NoSQL solutions with traditional RDBMS, we can generally identify a few features that are present in most of the NoSQL storage engines.
For instance, they usually treat objects in their very own way: when we look at RDBMS, objects are usually represented as rows in a “cluster” (table), and the cluster – by definition – includes elements with similar characteristics (properties, or “columns”).
An object, in a typical relational database, fits in this kind of structure:

and, for example, here’s how you would represent a certain type of objects, let’s say a “dog”:
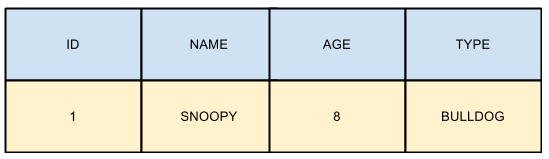
Even though this model, made by types (or clusters, or “tables”) and properties (“columns”) is really popular, there are certain scenarios in which data won’t fit that well in those fixed structures.
If we take a look at how Redis, a NoSQL key-value storage engine, organizes data instead, we would discover a totally opposite model, as it stores records in key-value pairs for the sake of performances: given this simple model, storing and retrieving data is very straightforward and, moreover, fast.
The question is, how would our dog record look into this new context?
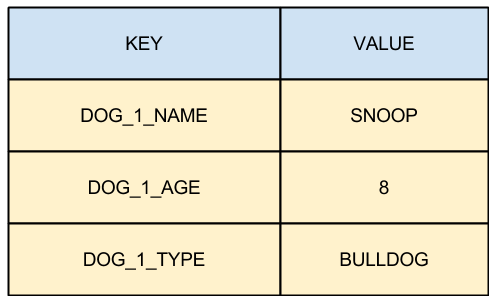
It is obvious that representing a structured object in a key-value engine seems very counter-intuitive, but as we said as the beginning of this chapter, it is a matter of context and requirements; a few would use Redis to store this kind of structured objects, if the application runs well, with good performances, on a RDBMS.
Salvatore Sanfilippo, the creator of Redis, developed this tool while working at a real-time data analytics platform, a tool similar to Google Analytics when GA did not have real-time statistics: given this context, of high-performances and weak data interconnection, could Redis be a good solution?
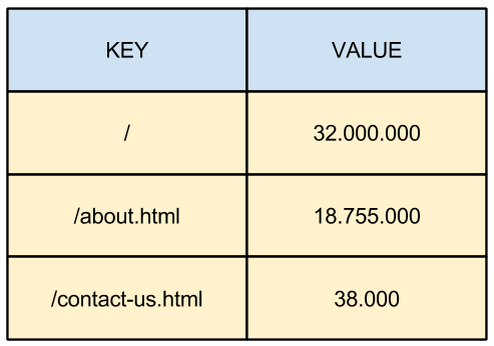
As you see in the image above, keys could represent unique identifiers for a webpage, while values would be the pageviews or simultaneous users for the given page: so, definitely, Redis has its own scenarios, and representing data as rows would bring no added value in those contexts.
Another data representation mechanism, different from the traditional rows or key-value pairs, is the document model, which OrientDB embraces: databases using this model organize objects as “documents”, which have the peculiarity of self-containing their very own properties that might differ from document to document, even if they belong to the same “class”.
For example, you may want to offer an animal-comparison service, and you need to store different types of animals in your database:
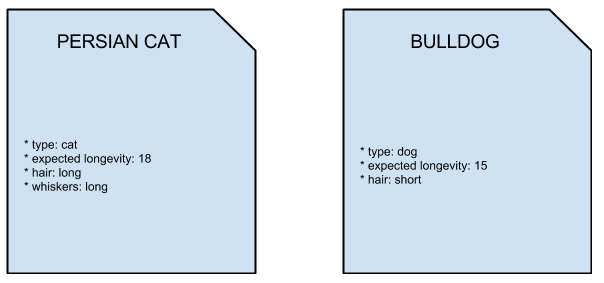
As you see, even though the record belong to the same family (animals), they
don’t share the same attributes: they are both documents, of the same class
(Animal), with their own attributes; documents give you the flexibility
in structuring data without the compromise of first designing your database
and then discover that your data does not fit in a common pattern.
OrientDB takes advatage of this model, handling records as documents, as you don’t have to declare a pre-defined structure for your data, and as a lot of document databases it can embed documents inside other documents: as you see in the image below, the dog document has an embedded record, which contains informations about the home country of that specific dog1:
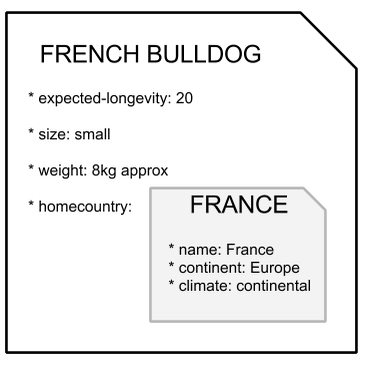
Realizing that data can be structured in different ways according to our requirements is the key to understand the choices that the creators of most of the NoSQL databases made to make their products a valuable alternative to traditional RDBMS: since storing data is subject to different patterns, it should come as no news the fact that one of the biggest advantages of these engine is being non-relational.
While this might come as no surprise, we would instead need to dig deep into the reason that pushed engineers towards developing these kind of solutions: given that the most limpid advantage that NoSQL engines bring while compared to RDBMS is their speed and flexibility, it might not sound strange that RDBMS’ most important feature – being relational – is also the biggest constriction that relational databases have.
Protocols
Since we are analyzing how OrientDB, being a NoSQL storage engine, differs from traditional RDBMS, we also need to consider the protocols that you would use to interact with it: a trend that NoSQL databases contributed to launch is to support different interfaces for interacting with the DB itself; for example CouchDB, a document database written in Erlang, was a pioneer in offering a REST interface to manage data.
OrientDB isn’t different as it support 2 different protocols indeed: one is its own proprietary binary protocol, the other one is the universal and very popular HTTP protocol; to interact with OrientDB we can decide either to bind it with its own protocol or to manage data from OrientDB’s HTTP/REST interface, which is, of course, very easy to understand and interact with.
And guess what, who of you would have thought that MySQL would add an HTTP interface these days? Sounds weird, right?
Where to go now?
At this point, it should be clear why we are analyzing a different way to storing data, as the NoSQL world gives a certain type of flexibility that would be impossible to achieve with traditional engines; at the same time we’ve also seen how OrientDB fully-embraces this new model and a question arises: is OrientDB just like any other NoSQL database?
The answer, pretty trivial, is no, and I will try to cover this topic in the next post of the series.
- BTW this is kind of a bad example as you obviously wouldn’t store the country as an embedded document, but you would just store a pointer to another record of class Country. But anyhow you understood the concept of embedded documents… ↩