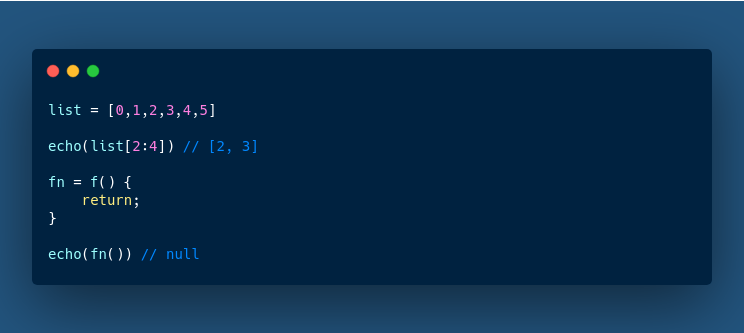
<![CDATA[Alessandro Nadalin]]>2022-11-18T09:33:53+00:00https://odino.org/Octopress<![CDATA[MySQL features I can’t wait for them to happen]]>2022-05-07T14:32:00+00:00https://odino.org/mysql-features-i-cant-wait-for-them-to-happen
]]>
Having worked with MySQL for over ten years, and having had the chance to
see other storage engines at work during my career, I’ve developed a list of
features that I’d like to see MySQL implement. The inspiration of this post comes
from the implementation of SKIP LOCKED in v8 — which was one of the items in my
bucket list :)
TTL
I recently bumped into Google Cloud Spanner’s TTL feature, which I love:
you can specify a policy to delete “old” rows from a table you don’t care
about anymore.
Over the course of my career I’ve had to setup a whole bunch of
jobs that would, at intervals, have to go and delete rows from a
table, and would be an enthusiastic user of this feature!
Record archival
Similar to the above, archival of records would be pretty neat.
I haven’t bumped into this problem just yet (or when I did, I simply
opted for getting rid of those old rows), but being able to support
record archival would be fun, for example by specifying a dynamic
set of tables records would end up in after a certain time:
and then you would need to go and query rider_location_2022_01
to get records that were initially inserted in January.
Implicit GROUPing
This is easily one of my biggest frustrations — having such a verbose
implementation of GROUP BY without being able to infer grouping columns
implicitly.
Countless of times I’ve made mistakes naming tables and DBs
(it’s one of the hard things at the end of the day!)
and I would love to be able to specify DB and table name aliases
without having to think about renaming / migrating them
altogether — table names are more manageable, so that’s
probably something I don’t really need (though it would still
be helpful to migrate tables used by different sets of apps eg.
writer and reader apps), but DB aliasing would make me fairly happy :)
Want more?
I’m sure I’m forgetting some big ticket item, but these above would
already make the ergonomics of working with MySQL a lot smoother for me.
What would you like to see in MySQL instead? Feel free to
reach out on twitter!
]]>
<![CDATA[Dell XPS 13 9310: USB-C port not recognizing external devices]]>2021-07-25T08:32:00+00:00https://odino.org/dell-xps-13-9310-usb-c-port-not-recognizing-external-devices
]]>
Just a quick one as I got back from my holidays and got taken aback
by a glitch in my XPS.
My right USB-C port stopped recognizing external devices yesterday:
it would be able to charge my laptop through the regular charger but
I couldn’t get it to recognize or charge neither my airpods or phone.
After digging a little bit around the Dell support forums I found
someone having luck by just restarting the laptop (though letting it rest
for a while).
So that’s exactly what I did — turned off the laptop, let it rest
for a few hours (actually, overnight) and then turn it back on again…
…and the problem was gone. Worth to notice that I also tried shutting
it down for 1/2m and didn’t work out.
I do believe this is a firmware issue, and I noticed it kicked in
by booting the laptop with a device connected to that port. Strange
world!
]]>
<![CDATA[Book review: Working Backwards]]>2021-07-24T07:42:00+00:00https://odino.org/book-review-working-backwards
]]>
I just got back from a week-long restorative holiday, where I found some
time to go back digging into my Kindle library.
Based on Faraz’s suggestion,
this time I picked up Working Backwards,
a book that revolves around Amazon’s culture, its unique approach to solving organizational
challenges and its pragmatic (albeit innovative) approaches to product development.
Little did I know this would be a great read, even though the style of the book
is definitely unconventional.
The book is really strange, in the sense that there doesn’t really seem to be
an agenda and is instead a bunch of chapters about what the authors think
created great competitive advantage for Amazon, loosely tied together. To be
honest, when you have to handpick a bunch of winning strategies for a company,
it’s probably hard to write a unidirectional story and instead should focus on
a bunch of anectodes (or mini-stories), which is what the authors do here, and
do extremely well.
It was incredibly insightful — for me, working at a high-growth, large-scale
company in a similar space, it provided a lot of key information about
problems we face while going through the same exact journey (even though
amazon’s problems are at planet-scale, while we mostly limit to our region).
I really enjoyed reading about the single-threaded leadership model (re-inforced my thoughts), as well as
the journey from a XML product feed to AWS (it’s brief, so don’t expect a lot
around AWS in this book). I also liked the practical examples around 6-pagers
as well as PR/FAQ documents: while I do believe too much narrative can slow
things down, I also recognize how important is to think things through, and the
fact that too many times I hit the ground running without a coherent and cohesive
plan. Another key takeway for me is focusing on input, as opposed to output,
metrics.
One anectode that got me cracking is the first in-person feedback session on the earlier
amazon APIs (aka XML product feeds), where someone who would then go on to have
a brilliant career at AWS showed up:
Since we did not have much experience creating programs for software developers, we sought in-person feedback from heavy users of the service. We decided to host an Amazon software developer conference in our Seattle headquarters. The first one attracted a grand total of eight people. We flew two of them in from Europe. I discovered, just a week before the conference, that one of the European attendees was a teenager. I had to check with our legal department if that was okay—fortunately we didn’t need permission from his parents, and he was able to join us at the conference. We worked out the logistics and set up a full day of sessions. Tim O’Reilly and Rael Dornfest from the O’Reilly Media, who were both avid supporters of the web services movement and taught us a lot about this new field, were there too. Another attendee was an avid customer who happened to live in Seattle. His name was Jeff Barr. He commented: The attendees were outnumbered by the Amazon employees. We sat and listened as the speakers talked about their plans to build on their success and to expand their web service offering over time. One speaker (it may have been Colin Bryar but I am not sure) looked to the future and said that they would be looking around the company for other services to expose in the future. This was the proverbial light-bulb moment for me! It was obvious that they were thinking about developers, platforms, and APIs and I wanted to be a part of it. Jeff Barr joined Amazon a few weeks later and is still with the company, serving as VP and chief evangelist for AWS.
Some other interesting quotes from the book:
bias for separable teams run by leaders with a singular focus that optimizes for speed of delivery and innovation
When I write about what led to Jeff making key decisions in this book, I can do so because I often directly asked him for his specific thinking behind his insights, as the reasoning behind them was often more illuminating than the insights themselves.
Before we start building, we write a Press Release to clearly define how the new idea or product will benefit customers, and we create a list of Frequently Asked Questions to resolve the tough issues up front. We carefully and critically study and modify each of these documents until we’re satisfied before we move on to the next step.
The meeting begins with everyone reading all the interview feedback. Afterward, the Bar Raiser may kick off the meeting by asking the group, “Now that everyone has had a chance to read all the feedback, would anyone like to change their vote?”
At many companies, the hiring manager has the recruiter make the offer. This is another mistake. The hiring manager should personally make the offer and sell him/her on the role and company. You may have chosen the candidate, but that doesn’t mean the candidate has chosen you. You must assume that good employees are being actively pursued by other companies, including their current employer. There is always the risk that you could lose the candidate. Nothing is certain until the day they report to the office.
employees should be able to say to themselves, “I’m glad I joined when I did. If I interviewed for a job today, I’m not sure I’d be hired!”
The best way to fail at inventing something is by making it somebody’s part-time job.
During this phase, we became aware of another, less positive trend: our explosive growth was slowing down our pace of innovation. We were spending more time coordinating and less time building. More features meant more software, written and supported by more software engineers, so both the code base and the technical staff grew continuously. Software engineers were once free to modify any section of the entire code base to independently develop, test, and immediately deploy any new features to the website. But as the number of software engineers grew, their work overlapped and intertwined until it was often difficult for teams to complete their work independently.
At last we realized that all this cross-team communication didn’t really need refinement at all—it needed elimination. Where was it written in stone that every project had to involve so many separate entities? It wasn’t just that we had had the wrong solution in mind; rather, we’d been trying to solve the wrong problem altogether. We didn’t yet have the new solution, but we finally grasped the true identity of our problem: the ever-expanding cost of coordination among teams. This change in our thinking was of course nudged along by Jeff. In my tenure at Amazon I heard him say many times that if we wanted Amazon to be a place where builders can build, we needed to eliminate communication, not encourage it.
The leader must have deep technical expertise, know how to hire world-class software engineers and product managers, and possess excellent business judgment.
While each two-pizza team crafted its own product vision and development roadmap, unavoidable dependencies could arise in the form of cross-functional projects or top-down initiatives that spanned multiple teams. For example, a two-pizza team working on picking algorithms for the fulfillment centers might also be called upon to add support for robotics being implemented to move products around the warehouse. We found it helpful to think of such cross-functional projects as a kind of tax, a payment one team had to make in support of the overall forward progress of the company. We tried to minimize such intrusions but could not avoid them altogether. Some teams, through no fault of their own, found themselves in a higher tax bracket than others. The Order Pipeline and Payments teams, for example, had to be involved in almost every new initiative, even though it wasn’t in their original charters.
The original idea was to create a large number of small teams, each under a solid, multidisciplined, frontline manager and arranged collectively into a traditional, hierarchical org chart. The manager would be comfortable mentoring and diving deep in areas ranging from technical challenges to financial modeling and business performance. Although we did identify a few such brilliant managers, they turned out to be notoriously difficult to find in sufficient numbers, even at Amazon. This greatly limited the number of two-pizza teams we could effectively deploy, unless we relaxed the constraint of forcing teams to have direct-line reporting to such rare leaders. We found instead that two-pizza teams could also operate successfully in a matrix organization model, where each team member would have a solid-line reporting relationship to a functional manager who matched their job description—for example, director of software development or director of product management—and a dotted-line reporting relationship to their two-pizza manager. This meant that individual two-pizza team managers could lead successfully even without expertise in every single discipline required on their team. This functional matrix ultimately became the most common structure, though each two-pizza team still devised its own strategies for choosing and prioritizing its projects.
Jeff has an uncanny ability to read a narrative and consistently arrive at insights that no one else did, even though we were all reading the same narrative. After one meeting, I asked him how he was able to do that. He responded with a simple and useful tip that I have not forgotten: he assumes each sentence he reads is wrong until he can prove otherwise. He’s challenging the content of the sentence, not the motive of the writer. Jeff, by the way, was usually among the last to finish reading.
Leadership and management are often about deciding what not to do rather than what to do. Bringing clarity to why you aren’t doing something is often as important as having clarity about what you are doing.
Input metrics measure things that, done right, bring about the desired results in your output metrics.
We soon saw that an increase in the number of detail pages, while seeming to improve selection, did not produce a rise in sales, the output metric. Analysis showed that the teams, while chasing an increase in the number of items, had sometimes purchased products that were not in high demand. This activity did cause a bump in a different output metric—the cost of holding inventory—and the low-demand items took up valuable space in fulfillment centers that should have been reserved for items that were in high demand. When we realized that the teams had chosen the wrong input metric—which was revealed via the WBR process—we changed the metric to reflect consumer demand instead. Over multiple WBR meetings, we asked ourselves, “If we work to change this selection metric, as currently defined, will it result in the desired output?” As we gathered more data and observed the business, this particular selection metric evolved over time from number of detail pages, which we refined to number of detail page views (you don’t get credit for a new detail page if customers don’t view it), which then became the percentage of detail page views where the products were in stock (you don’t get credit if you add items but can’t keep them in stock), which was ultimately finalized as the percentage of detail page views where the products were in stock and immediately ready for two-day shipping, which ended up being called Fast Track In Stock.
Charlie Bell, an SVP in AWS and a great operational guru at Amazon, put it aptly when he said, “When you encounter a problem, the probability you’re actually looking at the actual root cause of the problem in the initial 24 hours is pretty close to zero, because it turns out that behind every issue there’s a very interesting story.”
The deck is usually owned by someone in finance. Or more accurately, the data in the deck are certified as accurate by finance.
People like talking about their area, especially when they’re delivering as expected, and even more so when they exceed expectations, but WBR time is precious. If things are operating normally, say “Nothing to see here” and move along. The goal of the meeting is to discuss exceptions and what is being done about them. The status quo needs no elaboration.
He said, “Amazon has a decent chance of being the last place to buy CDs. The business will be high-margin but small. You’ll be able to charge a premium for CDs, since they’ll be hard to find.” Jeff did not take the bait. We were their guests and the rest of the meeting was uneventful. But we all knew that being the exclusive seller of antique CDs did not sound like an appealing business model. While it is tempting to suggest the meeting impacted Jeff’s thinking, only Jeff can speak to that. What we can say is what Jeff did and did not do afterward. What he didn’t do (and what many companies would have done) is to kick off an all-hands-on-deck project to combat this competitive threat, issue a press release claiming how Amazon’s new service would win the day, and race to build a copycat digital music service. Instead, Jeff took time to process what he learned from the meeting and formed a plan. A few months later, he appointed a single-threaded leader—Steve Kessel—to run Digital, who would report directly to him so that they could work together to formulate a vision and a plan for digital media. In other words, his first action was not a “what” decision, it was a “who” and “how” decision.
We applied the new two-pizza structure to every part of the org chart below Steve and his direct reports. The two-pizza structure became more complicated at the top of the org chart. For example, should product, engineering, and business functions all report to a single leader? Or should each one be run by its own leader, with those leaders in turn working as a team on the product, engineering, and business details? We decided that there would be separate leaders for business and tech for each digital product category—books, music, and video. Each of these category leaders would hire leaders for each business function, such as product management, marketing/merchandising, and vendor/content management (licensing digital content from publishers, studios, and record companies). Each general manager (GM) category leader had a corresponding peer leader on the engineering side. Each engineering category had a two-pizza team for each major component of the software services (e.g., content ingestion and transformation) and for client application software. This was mostly a pragmatic decision based on the skills of the leaders. For example, I had no experience at that time managing an engineering organization. The same was true of my peers on the engineering side with respect to business. This would change in the years to come.
Customer expectations are not static. They rise over time, which means you cannot rest on your laurels.
Jeff would say something like this to a leader who had just laid an egg: “Why would I fire you now? I just made a million-dollar investment in you. Now you have an obligation to make that investment pay off. Figure out and clearly document where you went wrong. Share what you have learned with other leaders throughout the company. Be sure you don’t make the same mistake again, and help others avoid making it the first time.”
Definitely recommended: there are some overlooked problems embedded in amazon’s ruthless
culture, but this book does a great job at explaining some of the things that worked
really well.
]]>
<![CDATA[fwupd is the best thing that ever happened to Linux]]>2021-04-15T10:41:00+00:00https://odino.org/fwupd-is-the-best-thing-that-ever-happened-to-linux
]]>
Honestly, I have no words:
$ fwupd.fwupdmgr refresh
WARNING: This package has not been validated, it may not work properly.Updating lvfsDownloading… [***************************************]Downloading… [***************************************]Successfully downloaded new metadata: 1 local device supported$ fwupd.fwupdmgr get-updates
WARNING: This package has not been validated, it may not work properly.Devices with no available firmware updates: • Integrated Webcam HD • KBG40ZPZ1T02 NVMe KIOXIA 1024GB • UEFI Device Firmware • UEFI Device Firmware • UEFI dbxXPS 13 9310 2-in-1│└─System Firmware: │ Device ID: [XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX] │ Current version: 1.1.1 │ Minimum Version: 1.1.1 │ Vendor: Dell Inc. (DMI:Dell Inc.) │ GUIDs: [XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX] │ [XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX] │ [XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX] │ Device Flags: • Internal device │ • Updatable │ • System requires external power source │ • Supported on remote server │ • Needs a reboot after installation │ • Cryptographic hash verification is available │ • Device is usable for the duration of the update │ └─XPS 13 9310 2-in-1 System Update: New version: 2.2.1 Remote ID: lvfs Summary: Firmware for the Dell XPS 13 9310 2-in-1 License: Proprietary Size: 26.7 MB Created: 2021-03-25 Urgency: Critical Vendor: Dell Inc. Flags: is-upgrade Description: This stable release fixes the following issues: • Fixed the issue where there is no audio output from the external monitor when you close the lid after restarting the system. Some new functionality has also been added: • Updated the Intel Management Engine to enhance the Thunderbolt connectivity. • Updated the Embedded Controller Engine firmware to enhance the battery life. • Added secondary function key that is Fn+Left as Home and Fn+Right as End.$ fwupd.fwupdmgr update
WARNING: This package has not been validated, it may not work properly.Devices with no available firmware updates: • Integrated Webcam HD • KBG40ZPZ1T02 NVMe KIOXIA 1024GB • UEFI Device Firmware • UEFI Device Firmware • UEFI dbxUpgrade available for System Firmware from 1.1.1 to 2.2.1XPS 13 9310 2-in-1 must remain plugged into a power source for the duration of the update to avoid damage. Continue with update? [Y|n]: Downloading… [***************************************] Less than one minute remaining…Decompressing… [***************************************]Authenticating… [***************************************]Authenticating… [***************************************]Updating System Firmware…[***************************************]Scheduling… [***************************************]Successfully installed firmwareAn update requires a reboot to complete. Restart now? [y|N]:
]]>
<![CDATA[Avoid battery draining on your Linux-flavored Dell XPS]]>2021-01-31T14:40:00+00:00https://odino.org/avoid-battery-draining-on-your-linux-flavored-dell-xps
]]>
Over the past few months my 2.5yo Dell XPS 13 has started showing signs of age,
and I had to worry both about my keyboard as well as the battery.
I haven’t really managed to replace the keyboard yet (I’m too scared of doing
it on my own, so I’ll wait to go back to the office and ask the IT folks
to do it for me), though I managed to replace the battery (got it from Noon) since my old one was at <40% capacity.
A factor that contributed to the battery’s demise was definitely the fact that,
through a recent kernel update, the laptop started shutting down in s2idle
sleep mode, which is short for “no bueno” — it basically means that the system
will use a pure software implementation of energy savings.
The fix is generally fairly easy — you can see what sleep state your
system is going to use by:
12
$ cat /sys/power/mem_sleep
[s2idle] deep
and a quick and easy fix is to switch to the deep state:
1
sudo bash -c "echo deep > /sys/power/mem_sleep"
Et-voila:
12
$ cat /sys/power/mem_sleep
s2idle [deep]
Now, as usual, this change is not going to be permanent, as we need to
register the kernel parameter either in systemd or grub, depending on what your system is running
on.
Remember: a battery will only last you ~500 charges, so making sure you save as much
energy as possible while the system is resting will allow you to defer a purchase by
months or years.
Adios!
]]>
<![CDATA[Combining two numbers into a unique one: pairing functions]]>2020-12-05T10:08:00+00:00https://odino.org/combining-two-numbers-into-a-unique-one-pairing-functions
]]>
Over the past couple of years I’ve grown my interest in image and data compression
— it’s a very interesting field, with a lot of interesting solutions to important
and lucrative problems (think Dropbox).
Over the past few days I was running some experiments and bumped into an interesting
concept: pairing positive integers into a “unique” number, with the ability to reverse
the operation.
Now, in the context of compression, pairing would only be useful when
the resulting integer can be consistently represented with less bits
than the original ones, and that’s where I’m still stuck at (more on this on a later post),
but I still wanted to share a couple interesting approaches I’ve bumped into.
Cantor pairing
The folks at Wolfram ask a very interesting question:
We all know that every point on a surface can be described by a pair of coordinates, but can
every point on a surface be described by only one coordinate?
And it actually turns out that the german mathematician Georg Cantor
had already develop a system to do exactly what we’ve been talking about, called
“cantor pairing”:
Now, I eventually bumped into this presentation from a Wolfram conference
15 years ago, and found another approach, which they call “elegant pairing”,
which seems to be a lot more straightforward, at least in terms of the algorithm’s
readability:
Well, I won’t go too deep into the realm of my thoughts so I’ll keep this
real simple: compression is all about communicating the same information,
but with less characters. When you say “jk” you’re compressing data (“just kidding”),
while the other party involved in the communication understands the “algorithm”
you’re using and is able to translate that the 2 characters “jk” effectively
mean “just kidding” (more than compression this is just a hashmap, but let me
have it for the day…).
Images like PNGs are usually just a bunch of pixels put together, with each pixel
represented by R, G, B and A (alpha transparency) values. Each value is represented
by 1 byte, so its maximum value can be 255 at most.
which is, theoretically, less characters than we started with.
Unfortunately for us, the max value one of our pair can have
(255, 255) is 65535, which takes 2 bytes to store, so even if
we end up with less “characters”, the number of bytes we need
to use to store them is exactly the same
(4 * 1 byte earlier, 2 * 2 bytes later) — so no bueno. I’ve opened
a can of worms that probably deserves its own post later on,
so I’ll keep my oversimplification for now and we’ll go on with
our lives :)
Adios!
]]>
<![CDATA[Running CI tests in Kubernetes through Github Actions]]>2020-03-20T09:21:00+00:00https://odino.org/running-ci-tests-in-kubernetes-through-github-actions
]]>
Today I’d like to show the other side of the medal — running your CI
environment on Kubernetes (through Github Actions).
It’s simple, mimics your production environment and it’s automated —
let’s get to it!
How Github Actions work
If you’ve ever used Travis CI or similar tools
you’re already familiar with Actions: they provide you an environment where
you can test your applications — generally in the form of a server with
your code checked out in a directory. When you push code to your Github
repository, an environment is booted, your code gets checked out and you
can run tasks on the environment — if any of the tasks fails, your CI
task fail.
This is not just useful for running automated tests — you could have
builds of your app being compiled in your CI environment and uploaded
to S3 or similar services, or send an email to your QA team to let them
know what tests are passing / failing.
So yes, you can think of Actions as Github booting a server, checking
out your code in there and giving you the option to run any command you
want on it — the actual implementation might be fairly different, but
this is all the eli5 you need right now.
Like having a server. What now?
If your development environment runs on a k8s cluster, or if you’re planning
to run your CI environment in k8s, having a machine to play with everytime
you push code to Github is like a manna from heaven: you can simply
setup a k8s cluster in there and watch your application run like it would
on production.
You might be skeptical about installing k8s in your CI environment for
a couple of very valid reasons:
installing k8s on a server is not always a straightforward operation
loads of moving parts that need to talk to each other (kubectl, apiserver, etcd, kubelet and so on),
so it could require quite some time to get everything up & running
Given that a CI environment should ideally be up in seconds,
the task of booting up a k8s cluster there seems quite daunting.
Luckily, the folks at Rancher got us covered:
they developed k3s, a lightweight Kubernetes distribution
geared towards IoT & edge computing — with the main selling point
being the fact that the cluster is up & running in a few seconds
with a simple:
1234
curl -sfL https://get.k3s.io | sh -
# wait ~30sk3s kubectl get node
With k3s, bringing k8s into our Action is extremely simple — let’s
see it in action!
The Kubernetes Github Action
First off, create your action file, eg. test.yml under the folder
.github/workflows in your repo — then add the following steps
to the workflow:
12345678910111213141516171819
name:Example actionon:[push]jobs:build:runs-on:ubuntu-latesttimeout-minutes:5steps:-uses:actions/checkout@v2-name:install k8srun:|curl -sfL https://get.k3s.io | K3S_KUBECONFIG_MODE=777 sh -cat /etc/rancher/k3s/k3s.yamlmkdir -p ~/.kubecp /etc/rancher/k3s/k3s.yaml ~/.kube/config-name:example testsrun:|# Whatever command you want to run
We download k3s, install it and copy its configuration into
the usual kubeconfig path. This is done so that kubectl
can talk to the cluster, else you have to use the one provided
by k3s under the alias k3s kubectl (meaning you need to run
commands such as k3s kubectl get po).
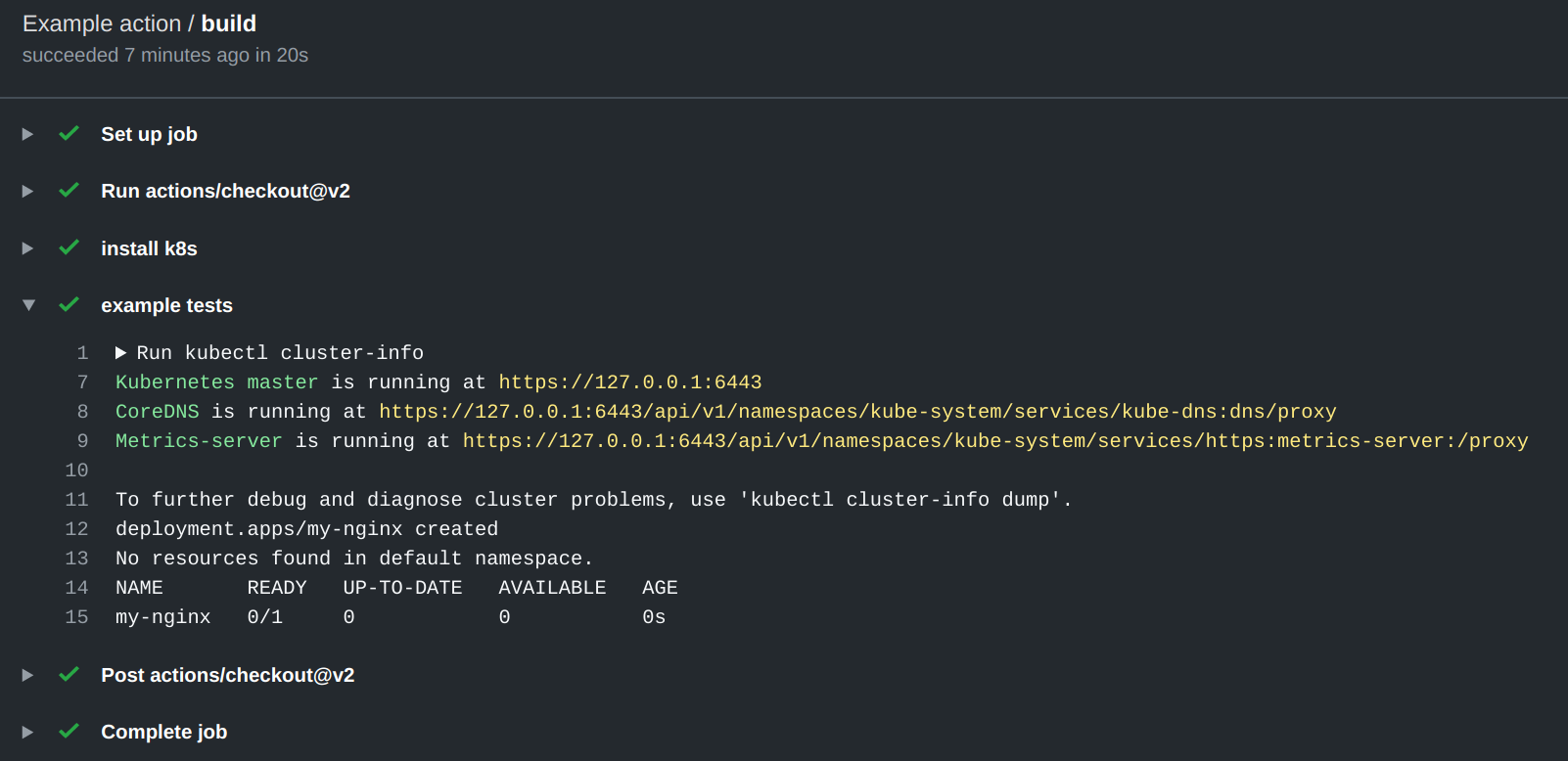
If you’re wondering how does this look like in action,
you should probably head over to the sample repo I
setup at github.com/odino/k8s-github-action:
it’s really not that crazy, as it simply contains the above
code. What you might find interesting, though, is having
a look at some of the “builds” that ran, where you can clarly
see k8s up & running:
]]>
<![CDATA[I've decided to make the WASEC ebook free during these trying times]]>2020-03-20T08:10:00+00:00https://odino.org/ive-decided-to-make-the-wasec-ebook-free-during-these-trying-times
]]>
Short post for the day to address an hopefully even shorter-lived situation
we’re all in.
I’ve decided to make the WASEC book free, on LeanPub, for the time being.
During these uncertain times, folks might find themselves home from their
jobs or, even worse, having to deal with the loss of their livelihood.
If you, like many others, are facing uncertain times and would want
to spend time learning and educating yourself on the topic of web application
security feel free to have one on me.
Update: 7th June 2020
The book is now back on sale for $9.99, as anticipated by my
tweet.
In line with my original announcement, I want to provide a path
for those who cannot afford the book, so feel free to
get in touch if unable to pay.
]]>
<![CDATA[Local k8s development in 2020]]>2019-12-31T15:45:00+00:00https://odino.org/local-k8s-development-in-2020
]]>
This decade’s about to wrap up, so I decided to spend some time
describing my development workflow as the year nears its end.
What I find interesting in my setup is that it entertains
working on a local k8s cluster — mainly to keep in touch
with the systems that run in production.
Running k8s locally isn’t what
you’d want to do to begin with, but rather a natural path
once you start wanting to replicate the environment that runs
your live applications. Again, you don’t need a local k8s
cluster just ‘cause, so make sure you have a good reason
before going through the rest of this article.
Cluster setup
Once a monstrous task, setting up a local k8s cluster is
now as simple as installing a package on your system:
Docker for Win/Mac allow you to run this very easily, and
Canonical has made it possible on Linux through microk8s
(that’s my boy!).
One of the funny things about running on microk8s
(or snaps, in general) is how it will automagically
upgrade under your nose — sometimes with breaking changes.
There was a recent change that swapped docker for containerd
as microk8s’ default container runtime, and it broke some
local workflows (more on that later, as it’s easy to fix).
In general, you can always force a snap to use a particular
revision, so if anything’s funky just downgrade and let others
figure it out :)
I’d be keen to try k3s out, as it seem to provide an even more
lightweight way to run the local cluster. Built mainly for
IoT and edge computing, k3s is interesting as running
microk8s is sometime resource-intesive — once I’m done
working on code, I usually prefer to sudo snap disable microk8s
in order to preserve RAM, CPU and battery life (proof here).
In the past, I’ve also tried to work on a remote k8s cluster
in the GKE from my local machine, but that proved to be too
much of a hassle — the beauty of kubectl is that you don’t
really care where the cluster is running, but your IDE and
other tools work best when everything is present and running
locally.
Development tool
This has been fairly stable until late this year, when I
decided to switch things around.
I’ve historically used helm and a bunch of shell magic
to run apps locally: you would clone a repo and expect
an helm/ folder to be available, with the chart being
able to install a whole bunch of k8s resources on your
cluster. Then, a bash script run simply apply the chart
with a bunch of pre-configured values: you would run dev up
and what the script would do would simply be something
along the lines of:
I started off with Helm 2, and v3 brought in a few changes I didn’t want to go through
helm is perfect if I want to package a generic app made up of multiple resources (service, ingress, etc) and release it to the outside world. Locally, I probably don’t need all of that verbosity (chart.yaml and so on)
most of the templating I did on development was {{ .Release.name }}. What’s the point then?
Towards the end of this year I went back to the drawing board
and started to think what if there was anything else I could
use that was simple enough and gave me enough flexibility.
I knew I could use simple k8s manifests but it wasn’t clear
to me how I could integrate it into my workflow in a way
that made it simpler than using a chart — and that’s when I
gave skaffold another chance.
Skaffold is an interesting tool, promoted by Google, that
supposedly handles local k8s development — and I say “supposedly”
because I’ve tried it in the past and have been extremely
underwhelmed by its workflow.
Let me explain: whenever a chance is detected in your codebase, skaffold
wants to redeploy your manifests but, rather than simply
working on an application-reload logic, is instead happy
to:
re-build your local image
push it to a registry
update the k8s deployment so a brand new pod comes up
If you’ve made it so far you probably realized that
the whole operation doesn’t either come cheap nor fast
— you could be waiting several seconds for your changes
to take effect…
That was, until skaffold introduced file sync
to avoid the need to rebuild, redeploy and restart pods.
This feature is currently in beta, but it’s already working
well enough that I’ve decided to give it a shot, with very
positive results.
Now, rather than having an entire chart to mantain locally,
my development setup has a simple skaffold.yaml that
looks like:
That’s about it. Now my dev up is mapped to a simple
skaffold dev, and skaffold takes care of re-building
the image when needed, syncing changes locally and so on.
One of the advantages of using this tool is that it automatically
detects changes to the manifests and the Dockerfile, so
it re-builds the image without you having to trigger the
process manually (which wasn’t possible with Helm alone).
Another interesting benefit of using skaffold is the support
for base registries as well as build stages. The former
allows you to run a registry at any given URL, and tell
skaffold to prepend that URL to any image that’s being pushed
to the k8s cluster.
As I mentioned, I use microk8s, which doesn’t play very well
with locally-built images,
so I simply run the built-in registry on port 32000. Others
in my team simply run Docker for Mac which doesn’t need a registry
as any image built locally is automatically available to k8s.
This would mean that I would have to update the image field
of my deployments, manually, to localhost:32000/my_app, a
tedious and annoying operation (and I’d also have to make sure
those changes aren’t pushed to git). Skaffold frees you from the
drama with a simple skaffold config set default-repo localhost:32000,
a trick that will tell skaffold to parse all the manifests it deploys
and replace the image fields, prepending the URL of your own registry.
The feature is documented extensively here,
and it’s a life saver!
The support for build stages is another great trick up in
skaffold’s sleeve, as it allows to use the power of Docker’s
multi-stage builds in your development environment.
If you have a Dockerfile that looks like:
123456789101112131415
FROM golang:1.13 as devRUN go get -v github.com/codegangsta/ginWORKDIR /srcCOPY go.mod /srcCOPY go.sum /srcRUN go mod downloadCOPY . /srcRUN go build -o my_go_binary main.goCMD gin run main.goFROM gcr.io/distroless/base as prodCOPY --from=dev /src /CMD ["/my_go_binary"]
You can tell skaffold that, locally, it should simply stop at the
dev stage:
Believe me, skaffold has made my life so much easier and it’s a tool
I would gladly recommend. Before introducing file syncing I didn’t
want to get my hads dirty with it, as I did not find the development
workflow sustainable (re-build and re-deploy at every file change),
but right now it works much better than anything I could have come
up with on my own.
Hands on the code
Last but not least, we went over running a cluster as well as our
application — but how do we actually debug our code or run tests?
Ideally, we’d like a script that would be able to:
build and run your app (up)
execute commands inside the container (exec)
jump inside the container (in)
execute tests (test)
Wouldn’t it be nice to simply open a shell and run your tests with dev test?
Turns out, creating a simple wrapper over our wokflow is very
straightforward, and here’s a sample of the code one could write:
#!/bin/bash# dev $commandarg=$1command="cmd_$1"# Boot the app through skaffold.cmd_up(){ skaffold dev
}# Deletes the appcmd_delete(){ skaffold delete
}# This will drop you inside the container.# We use bash, if available, else "sh"cmd_in(){app=$(get_app_name) kubectl exec -ti deploy/$app -- sh -c "command -v bash && bash || sh"}# Read the app name based on the image we# build inside the skaffold.yamlget_app_name(){echo$(yq read skaffold.yaml build.artifacts.0.image)}# Main function: if a command has been passed,# check if it's available, and execute it. If# the command is not available, we print the# default help.main(){declare -f $command > /dev/null
if[$? -eq 0 ]then$command$@elseprintf"'$arg' is not a recognized command.\n\n"exit 1
fi}shiftmain $@
All this script does is to read the command passed to it
and run it as a bash function. As you see, up is mapped
to skaffold dev, and in is mapped to kubectl exec ... -- bash
(so that you can jump into the container and run whatever
command you’d like).
The actual dev I run locally is on github, under odino/k8s-dev,
and I believe I should credit Hisham for the original idea
— this is a script we’ve been using (and polishing) since ages.
If you’re wondering how does it look on the
terminal, here’s an asciicast where tests
are run succesfully (dev test), we update
the code to make the tests fail and then
we jump into the container (dev in), before
cleaning up (dev delete):
That’s a wrap
Oh boy, right on time to close 2019 with a splash!
Developing on a local k8s cluster isn’t super straightforward,
and I hope that by sharing my toolbox it should be easier for
you to set your environment up for a productive day.
Happy new decade!
]]>
<![CDATA[WASEC, a book about Web Application Security, is now available for sale]]>2019-11-25T22:41:00+00:00https://odino.org/wasec-a-book-about-web-application-security-is-now-available-for-sale
]]>
I’m pleased to announce (even though you might have already heard about this on my Twitter stream)
that the ebook on web application security I’ve been working on over the past year is now
officially available for sale, at the hopefully-reasonable price of $6.99 $9.99.
You can now buy the book at leanpub.com/wasec, while Kindle enthusiasts will
have to wait a few more days for it to become available there: it is currently available for pre-order
and should be generally available in the next few days.
WASEC is the culmination of over a year of thoughts regarding my experience with web application
security from the point of view of a software engineer, rather than the one of a security researcher.
I believe software engineers might find it extremely interesting as it approaches defensive security
from the point of view of someone who has to build an app and needs to keep security into consideration
among other things.
If you’re unsure about purchasing the ebook you can take a look at some of its content that I previously
shared in this blog. If reading lengthy blog posts isn’t
your thing, you can also download the sample version from leanpub itself — it contains the first few
complete chapters of the book.
What if I can’t afford the book?
Reach out to me privately, and we’ll sort something out. I will need to make sure you’re not trying
to gamble the system, but I’d hate to see someone not being able to read the book simply because they
can’t afford it — I will try to make an effort to reply to everyone who reaches out to me, and make sure
financial conditions don’t get in the way of knowledge.
I wrote this book to share what my experience with
web security has been and, frankly, I don’t think I’ll ever make the money I spent on it (in terms of man-hours)
ever — so there’s no point in being greedy :–)
Again, ping me and we’ll try to work something out.
Sayonara
Again, please make sure you visit WASEC’s book page on leanpub and,
if you’re interested in the topic and have a few bucks to spare, buy the book. Leanpub has a 45-day “100% Happiness Guarantee”,
which means there’s no risk in purchasing any Leanpub book, and they make it easy to get a refund if you’ve tried
a book and want your money back within 45 days of your purchase. If you end up reading the book, feel free to reach
out and let me know what your thoughts are.
In the next few days I’ll be publishing some more updates to the book (all future updates will be available for
free for users who have purchased it) and release it on the Kindle store — hit me up if you have any question.
Adios!
]]>
<![CDATA[Web application security: what to do when...]]>2019-10-28T14:43:00+00:00https://odino.org/wasec-web-application-security-what-to-do-when-dot-dot-dot
]]>
This post is part of the ”WASEC: Web Application SECurity” series, which is a portion of the content of WASEC, an e-book on web application security I’ve written.
Here is a list of all the articles in this series:
If you’ve enjoyed the content of this article, consider buying the complete ebook on either the Kindle store or Leanpub.
Often times, we’re challenged with decisions that have a direct impact on the security of our applications, and the consequences of those decisions could potentially be disastrous. This article aims to present a few scenarios you might be faced with, and offer advice on how to handle each and every single of them.
This is by no means an exhaustive list of security considerations you will have to make in your day to day as a software engineer, but rather an inspiration to keep security at the centre of your attention by offering a few examples.
Blacklisting versus whitelisting
When implementing systems that require discarding elements based on an input (eg. rejecting requests based on an IP address or a comment based on certain words) you might be tempted to use a blacklist in order to filter elements out.
The inherent problem with blacklist is the approach we’re taking: it allows us to specify which elements we think are unsafe, making the strong assumption of knowing everything that might hurt us. From a security perspective, that’s the equivalent of us wearing summer clothes because we’re well into June, without looking out the window in order to make sure today’s actually sunny: we make assumptions without having the whole picture, and it could hurt us.
If you were, for example, thinking of filtering out comments based on a blacklist of words, you would probably start by describing a blacklist of 5 to 10 words: when coming up with the list you might be forgetting words such a j3rk, or reject genuine comments mentioning “Dick Bavetta”, a retired NBA referee.
Now, comments aren’t always the most appropriate example in terms of security, but you get the gist of what we’re talking about: it’s hard to know everything that’s going to hurt us well in advance, so whitelisting is generally a more cautious approach, allowing us to specify what input we trust.
A more practical example would be logging: you will definitely want to whitelist what can be logged rather than the opposite. Take an example object such as:
You could possibly create a blacklist that includes password and credit_card, but what would happen when another engineer in the team changes fields from snake_case to camelCase?
You might end up forgetting to update your blacklist, leading to the credit card number of your customers being leaked all over your logs.
As you’ve probably realized, the choice of utilizing a blacklist or a whitelist highly depends on the context you’re operating in: if you’re exposing a service on the internet (such as facebook.com), then blacklisting is definitely not going to work, as that would mean knowing the IP address of every genuine visitor, which is practically impossible.
From a security perspective, whitelisting is definitely a better approach, but is often impactical. Choose your strategy carefully after reviewing both options: none of the above is suitable without prior knowledge of your system, constraints and requirements.
Logging secrets
If you develop systems that have to deal with secrets such as passwords, credit card numbers, security tokens or personally identifiable information (abbr. PII), you need to be very careful about how you deal with these data within your application, as a simple mistake can lead to data leaks in your infrastructure.
Take a look at this example, where our app fetches user details based on a header:
12345678
app.get('/users/me',function(req,res){try{user=db.getUserByToken(req.headers.token)res.send(user)}catch(err){log("Error in request: ",req)}})
Now, this innocuous piece of code is actually dangerous: if an error occurs, the entire request gets logged.
Having the whole request logged is going to be extremely helpful when debugging, but will also lead to storing auth tokens (available in the request’s headers) in our logs: anyone who has access to those logs will be able to steal the tokens and impersonate your users.
You might think that, since you have tight restrictions on who has access to your logs, you would still be “safe”: chances are that your logs are ingested into a cloud service such as GCP’s StackDriver or AWS’ CloudWatch, meaning that there are more attack vectors, such as the cloud provider’s infrastructure itself, the communication between your systems and the provider to transmit logs and so on.
The solution is to simply avoid logging sensitive information: whitelist what you log (as we’ve seen in the previous paragraph) and be wary of logging nested entities (such as objects), as there might be sensitive information hiding somewhere inside them, such as our req.headers.token.
Another solution would be to mask fields, for example turning a credit card number such as 1111 2222 3333 4444 into **** **** **** 4444 before logging it.
That’s sometimes a dangerous approach: an erroneous deployment or a bug in your software might prevent your code from masking the right fields, leading to leaking the sensitive information. As I like to say: use it with caution.
Last but not least, I want to mention one particular scenario in which any effort we make not to log sensitive information goes in vain: when users input sensitive information in the wrong place.
You might have a login form with username and password, and users might actually input their password in the username field (this can generally happen when you “autoremember” their username, so that the input field is not available the next time they log in). Your logs would then look like this:
123
user e0u9f8f484hf94 attempted to login: failure
user lebron@james.com attempted to login: success
...
Anyone with access to those logs can figure an interesting pattern out: if a username doesn’t follow an email pattern (email@domain.tld), chances are the string is actually a password the user had wrongly typed in the username field. Then you would need to look at the successful login attempts been made shortly after, and try to login with the submitted password against a short list of usernames.
What is the point here? Security is hard and, most often, things will work against you: in this context, being paranoid is a virtue.
Who is silly enough to log a password?
You might think logging sensitive information is an amateur’s mistake, but I argue that even experienced programmers and organizations fall fall under this trap. Facebook, in early 2019, suffered a security incident directly related to this problem. As Brian Krebs put it:
“Facebook is probing a series of security failures in which employees built applications that logged unencrypted password data for Facebook users and stored it in plain text on internal company servers.”
This is not to say that Facebook should not be held accountable for the incident, but rather that we can probably sympathize with the engineers who forgot the console.log somewhere in the code. Security is hard, and so making sure we pay extra-attention to what we log is an extremely important matter.
Never trust the client
As we’ve seen before, cookies that are issued by our servers can be tampered with, especially if they’re not HttpOnly and are accesible by JS code on your page.
At the same time, even if your cookies are HttpOnly, storing plaintext data in them is not secure, as any client (even curl), could get a hold of those cookie, modify them and re-issue a request with a modified version of the original cookie.
Suppose your session cookie contains this information:
1
profile=dXNlcm5hbWU9TGVCcm9uLHJvbGU9dXNlcg==;
The string is base64-encoded, and anyone could reverse it to get to its actual value, username=LeBron,role=user. Anyone could, at that point, replace user with admin and re-encode the string, altering the value of the cookie.
If your system trusts this cookie without any additional check, you’re in for trouble. You should instead never trust the client, and prevent it from being able to easily tamper with the data you’ve handed off. A popular workaround to this issue is to encrypt or sign this data, like JSON Web Tokens do.
Let’s drift for a second and dive into JWT, as their simplicity lets us understand the security mechanism behind them extremely well. A JWT is made of 3 parts: headers, claims and signature, separated by a dot:
1
JWT = "$HEADER.$CLAIMS.$SIGNATURE"
Each value is base64-encoded, with header and claims being nothing but an encoded JSON object:
123456789101112
$HEADER = BASE64({
"alg": "HS256", # HMAC SHA 256
"typ": "JWT" # type of the token
})
$CLAIMS = BASE64({
"sub": "1234567890", # ID of the user
"name": "John Doe", # Other attributes...
"iat": 1516239022 # issued at
})
JWT = "$HEADER.$CLAIMS.$SIGNATURE"
The last part, the signature, is the Message Authentication Code (abbr. MAC) of the combined $HEADER.$CLAIM, calculated through the algorithm specified in the header itself (HMAC SHA-256 in our case). Once the MAC is calculated, it is base64-encoded as well:
If you followed this far, you might have understood that JWT is simply composed of 3 parts: 2 insecure set of strings and a signed one, which is what is used to verify the authenticy of the token. Without the signature, JWTs would be insecure and (arguably) useless, as the information they contain is simply base64-encoded.
As a practical example, let’s have a look at this token:
That’s the mechanism JWTs use to prevent clients from tampering with the tokens themselves: when a server validates a token, it will first verify its signature (through the public key associated by the private one used to generate the signature), then access the token’s data. If you’re planning to hand over critical information to the client, signing or encrypting it is the only way forward.
Are JWTs safe?
JWTs have been under a lot of scrutiny in recent years, partly because of some design flaws that had to be course-corrected, such as the support of a ‘None’ algorithm which would effectively allow forging tokens without any prior knowledge of secrets and keys used to sign them. Luciano Mammino, a researcher from Italy, even managed to publish a JWT cracker to illustrate how easy it could be to crack JWTs through brute-forcing, granted the algorithm and secrets used are weak.
In all honesty, JWTs are very useful when you want to exchange data between two parties. For example, you could send a client the URL https://example.com/check-this-message?token=$JWT so that they could access the data within the token and know it comes from a trusted source. As session IDs, often times there are simpler mechanism you should rely on, as you only really need to issue a cryptographically random ID that identifies a client.
Does this mean JWTs are not safe? Not really, as it depends on how you use them: Google, for example, allows authentication to their APIs through JWTs, like many others; the trick is to use safe, long secrets or a cryptographically secure signing algorithm, and understand the use-case you’re presented with. JWTs also don’t make any effort to encrypt the data they hold, and they’re only concerned with validating its authenticity: understand these trade-offs and make your own educated choice.
In addition, you might want to consider PASETO, “Platform Agnostic SEcurity TOkens”: they were designed with the explicit goal to provide the flexibility and feature-set of JWTs without some of the design flaws that have been highlighted earlier on.
It should go without saying, but your session IDs (often stored in cookies) should not resemble a know pattern, or be generally guessable. Using an auto-icrementing sequence of integers as IDs would be a terrible choice, as any attacker could just log in, receive session id X and then replace it with X ± N, where N is a small number to increase chances of that being an identifier of a recent, thus valid, session.
The simplest choice would be to use a cryptographically secure function that generates a random string, and usually that’s not a hard task to accomplish. Let’s, for example, take the Beego framework, very popular among Golang developers, as an example: the function that generates session IDs is
123456789101112131415161718
packagesessionimport("crypto/rand")// ...// ...// ...func(manager*Manager)sessionID()(string,error){b:=make([]byte,manager.config.SessionIDLength)n,err:=rand.Read(b)ifn!=len(b)||err!=nil{return"",fmt.Errorf("Could not successfully read from the system CSPRNG")}returnmanager.config.SessionIDPrefix+hex.EncodeToString(b),nil}
6 lines of code, secure session IDs. As we mentioned earlier, no magic needs to be involved. In general, in most cases you won’t need to write this code yourself, as frameworks would provide the basic building blocks to secure your application out of the box: if you’re in doubt, though, you can review the framework’s code, or open an issue on GitHub to clarify your security concern.
Querying your database while avoiding SQL injections
But guess what, injections made the #1 spot in the 2010 and 2013 version of the same list as well, and so there’s a strong chance you might be familiar with any type of injection risk. To quote what we discussed earlier in this chapter, the only thing you need to remember to fight injection is to never trust the client: if you receive data from a client, make sure it’s validated, filtered and innocuous, then pass it to your database.
A typical example of an injection vulnerability is the following SQL query:
1
SELECT*FROMdb.usersWHEREname="$name"
Suppose $name comes from an external input, like the URL
https://example.com/users/search?name=LeBron: an attacker can then craft a specific value for the variable that will significantly alter the SQL query being executed. For example, the URL https://example.com/users/search?name=anyone%22%3B%20TRUNCATE%20TABLE%20users%3B%20-- would result in this query being executed:
This query would return the right search result, but also destroy the users’ table, with catastrophic consequences.
Most frameworks and libraries provide you with the tools needed to sanitize data before feeding it to, for example, a database. The simplest solution, though, is to use prepared statements, a mechanism offered by most databases that prevents SQL injections altogether.
Prepared statements: behind the scenes
Wondering how prepared statements work? They’re very straightforward, but often misunderstood. The typical API of a prepared statement looks like:
query = `SELECT * FROM users WHERE id = ?` db.execute(query, id)
As you can see, the “base” query itself is separated from the external variables that need to be embedded in the query: what most database drivers will eventually do is to first send the query to the database, so that it can prepare an execution plan for the query itself (that execution plan can also be reused for the same query using different parameters, so prepared statements have performance benefits as well). Separately, the driver will also send the parameters to be used in the query.
At that point the database will sanitize them, and execute the query together with the sanitized parameters.
There are 2 key takeaways in this process:
the query and parameters are never joined before being sent to the database, as it’s the database itself that performs this operation
you delegate sanitization to a built-in database mechanism, and that is likely to be more effective than any sanitization mechanism we could have come up by ourselves
Dependencies with known vulnerabilities
Chances are that the application you’re working on right now depends on a plethora of open-source libraries: ExpressJS, a popular web framework for NodeJS, depends on 30 external libraries, and those libraries depend on…we could go on forever. As a simple exercise, I tried to install a brand new version of ExpressJS in my system, with interesting results:
1234
$ npm install express
+ express@4.17.1added 50 packages from 37 contributors and audited 127 packages in 9.072sfound 0 vulnerabilities
Just by installing the latest version of ExpressJS, I’ve included 50 libraries in my codebase. Is that inherently bad? Not at all, but it presents a security risk: the more code we write (or use), the larger the attack surface for malicious users.
One of the biggest risks when using a plethora of external libraries is not following up on updates when they are released: it isn’t so bad to use open-source libraries (after all, they probably are safer than most of the code we write ourselves), but forgetting to update them, especially when a security fix gets released, is a genuine problem we face every day.
Luckily, programs such as npm provide tools to identify outdated packages with known vulnerabilities: we can simply try to install a dependency with a known vulnerability and run npm audit fix, and npm will do th job for us.
1234567891011121314151617181920212223242526272829
$ npm install lodash@4.17.11
+ lodash@4.17.11added 1 package from 2 contributors and audited 288 packages in 1.793sfound 1 high severity vulnerability run `npm audit fix` to fix them, or `npm audit` for details$ npm audit
=== npm audit security report === # Run npm update lodash --depth 1 to resolve 1 vulnerability
┌───────────────┬──────────────────────────────────────────────────────────────┐│ High │ Prototype Pollution │├───────────────┼──────────────────────────────────────────────────────────────┤│ Package │ lodash │├───────────────┼──────────────────────────────────────────────────────────────┤│ Dependency of │ lodash │├───────────────┼──────────────────────────────────────────────────────────────┤│ Path │ lodash │├───────────────┼──────────────────────────────────────────────────────────────┤│ More info │ https://npmjs.com/advisories/1065 │└───────────────┴──────────────────────────────────────────────────────────────┘found 1 high severity vulnerability in 1 scanned package run `npm audit fix` to fix 1 of them.$ npm audit fix
+ lodash@4.17.15updated 1 package in 0.421sfixed 1 of 1 vulnerability in 1 scanned package
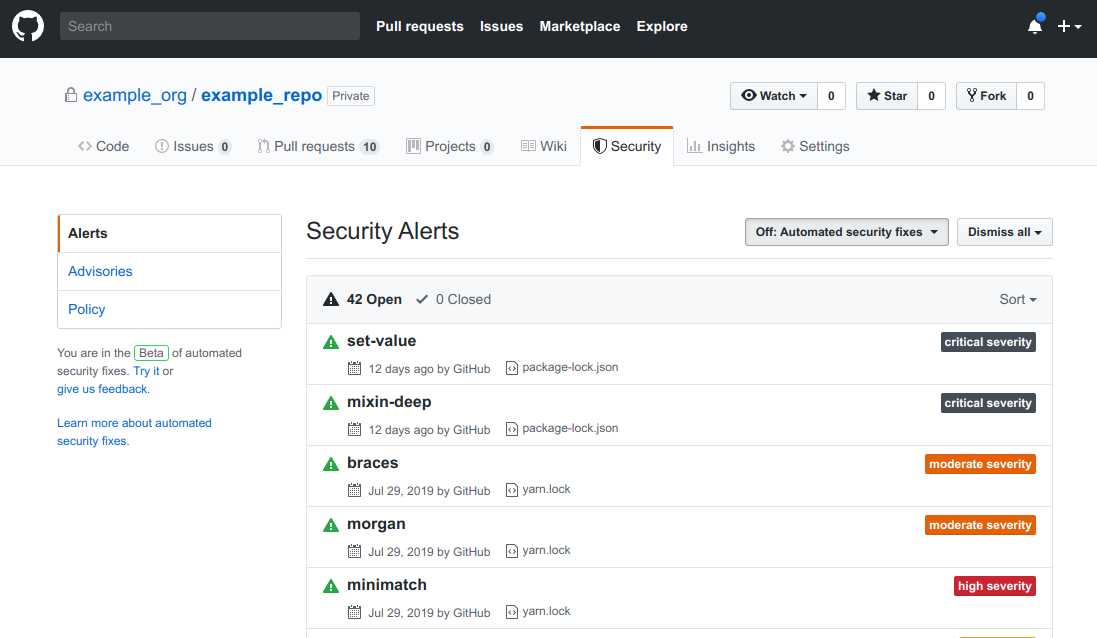
If you’re not using JavaScript and npm, you can always rely on external services to scan your software and let you know if any library with known vulnerabilities is found: GitHub offers this service for all their repositories, and you might find it convenient when your codebase is already hosted there.
GitHub will also send you an email every time a dependency with a known vulnerability is detected, so you can head over to the repository and have a look at the problem in detail.
If you prefer using a different platform, you could try gitlab.com: it acquired Gemnasium, a product that offered vulnerability scanning, in early 2018 in order to compete with GitHub’s offering. If you prefer to use a tool that does not require code hosting instead, snyk.io would probably be your best bet: it’s trusted by massive companies such as Google, Microsoft and SalesForce, and offers different tools for your applications, not just dependency scanning.
Have I been pwned?
Remember when you were a teenager, and signed up for your first online service ever? Do you remember the password you used? You probably don’t, but the internet might.
Chances are that, throughout your life, you’ve used an online service that has been subject to attacks, with malicious users being able to obtain confidential information, such as your your password. I’m going to make it personal here: my email address has been seen in at least 10 public security breaches, including incidents involving trustworthy companies such as LinkedIn and Dropbox.
How do I know?
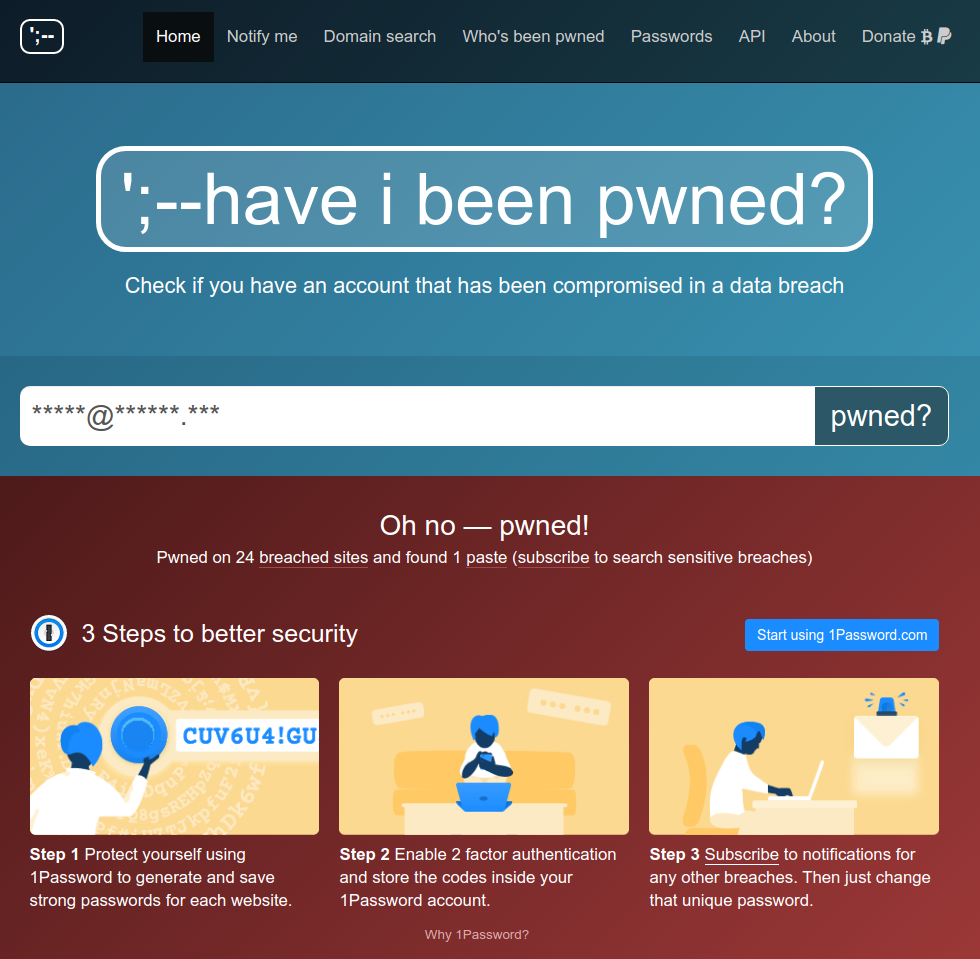
I use a very interesting service called haveibeenpwned.com (abbr. HIBP), created by Troy Hunt, an Australian web security expert. The site collects information about public data breaches and allows you to understand whether your personal information was seen in any of these breaches. There’s no shame in being involved in one of these data breaches, as it’s not really your fault. This is, for example, the result of looking up the email address of Larry Page, one of Google’s co-founders:
Larry’s email address has been masked, but it’s pretty public information
By knowing when and where an incident happened, you can take a few actions to improve your personal security posture, such as activating two-factor authentication (abbr. 2FA) and being notified of a breach as soon as HIBP is.
One of the interesting side-effects of HIBP is, though, the ability to use it to improve your business’ security, as the site offers an API that you can use to verify whether users within your organization were involved in a data breach. This is extremely important as, too often, users consider security an afterthought, and opt out of mechanisms such as 2-factor authentication. This quickly becomes disastrous when you put in context of password re-use, a practice that is still way too common: a user signing up to multiple services using the same exact password. When one of those services is breached, the accounts on all the other ones might be breached as well.
Re-using credentials: a real-world story
I’ve been directly hit by a password re-use attack during my career, and it wasn’t a fun experience.
While I was heading technology at an online company, our security team received a message from a (questionable) researcher claiming he could login into many of our user accounts, sending across plaintext passwords to prove the fact. Baffled, we quickly realized we either got compromised, or someone else had been: when the attacker revealed *how* he got those credentials, we quickly realized they were available to the public through some hardcore googling.
After obtaining a full list of emails included in the breach, we then had to join it with the list of our customers, ending with forcefully resetting the password of the ones found both in the breach and our own database.
Session invalidation in a stateless architecture
If you’ve ever built a web architecture, chances are that you’ve heard how stateless ones scale better due to the fact that they do not have to keep track of state. That is true, and it represents a security risk, especially in the context of authentication state.
In a typical stateful architecture, a client gets issued a session ID, which is stored on the server as well, usually linked to the user ID. When the client requests information from the server, it includes its session ID, so that the server knows that a particular request is made on behalf of a user with a particular ID, thanks to the mapping between session and user IDs. This requires the server store a list of all the session IDs it generated with a link to the user ID, and it can be a costly operation.
JWTs, which we spoke about earlier on in this chapter, rose to prominence due to the fact that they easily allow stateless authentication between the client and the server, so that the server would not have to store additional information about the session. A JWT can include a user id, and the server can simply verify its signature on-the-fly, without having to store a mapping between a session ID and a user ID.
The issue with stateless authentication tokens (and not just JWTs) lies in a simple security aspect: it is supposedly hard to invalidate tokens, as the server has no knowledge of each one it generated since they’re not stored anywhere. If I logged in on a service yesterday, and my laptop gets stolen, an attacker could simply use my browser and would still be logged in on the stateless service, as there is no way for me to invalidate the previously-issued token.
This can be easily circumvented, but it requires us to drop the notion of running a completely stateless architecture, as there will be some state-tracking required if we want to be able to invalidate JWTs. The key here is to find a sweet spot between stateful and stateless, taking advantage of both the pros of statelessness (performance) and statefulness (security).
Let’s suppose we want to use JWTs for authentication: we could issue a token containing a few information fo the user:
As you can see, we included a the issued at (iat) field in the token, which can help us invalidating “expired” tokens. You could then implement a mechanism whereby the user can revoke all previously issued tokens by simply by clicking a button that saves a timestamp in a, for example, last_valid_token_date field in the database.
The authentication logic you would then need to implement for verifying the validity of the token would look like this:
Easy-peasy! Unfortunately, this requires you to hit the database everytime the user logs in, which might go against your goal of scaling more easily through being state-less. An ideal solution to this problem would be to use 2 tokens: a long-lived one and a short-lived one (eg. 1 to 5 minutes).
When your servers receive a request:
if it only has the long-lived one only, validate it and do a database check as well. If the process is successful, issue a new short-lived one to go with the long-lived one
if it carries both tokens, simply validate the short-lived one. If it’s expired, repeat the process on the previous point. If it’s valid instead, there’s no need to check the long-lived one as well
This allows you to keep a session active for a very long time (the validity of the long-lived token) but only check for its validity on the database every N minutes, depending on the validity of the short-lived token. Every time the short-lived token expires, you can go ahead and re-validate the long-lived one, hitting the database.
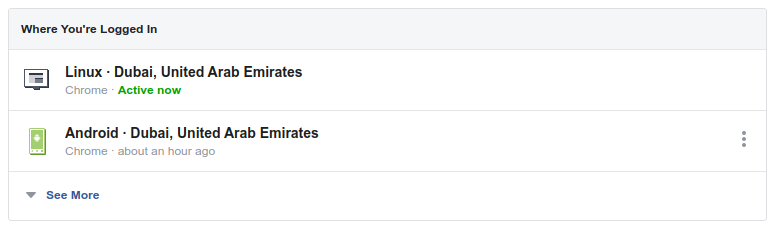
Other major companies, such as Facebook, keep track of all of your sessions in order to offer an increased level of security:
This approach definitly “costs” them more, but I’d argue it’s essential for such a service, where the safety of its user’s information is extremely important. As we stated multiple times before, choose your approach after carefully reviewing your priorities, as well as your goals.
My CDN was compromised!
Often times, web applications serve part of their content through a CDN, typically in the form of static assets like Javascript or CSS files, while the “main” document is rendered by a webserver. This gives developers very limited control over the static assets themselves, as they’re usually uploaded to a 3rd-party CDN (eg. CoudFront, Google Cloud CDN, Akamai).
Now, suppose an attacker gained access to your login credentials on the CDN provider’s portal and uploaded a modified version of your static assets, injecting malicious code. How could you prevent such a risk for your users?
Browser vendors have a solution for you, called sub-resource integrity (abbr. SRI). Long-story short, SRI allows your main application to generate cryptographic hashes of your static files and tell the browser which file is mapped to what hash. When the browser downloads the static asset from the CDN, it will calculate the asset’s hash on-the-fly, and make sure that it matches the one provided in the main document. If the hashes don’t match the browser will simply refuse to execute or render the asset.
This is how you can include an asset with an integrity hash in your document:
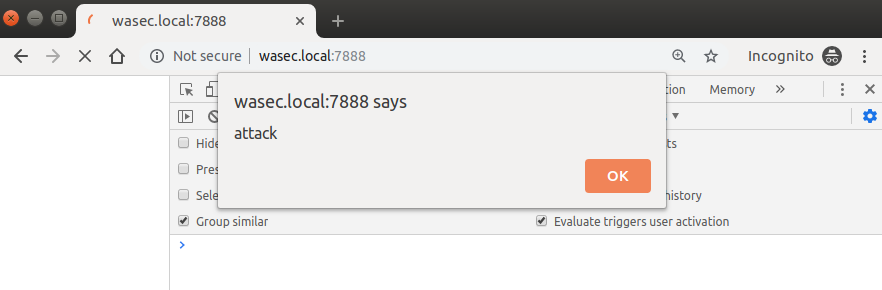
Two scripts are included in the page you’re opening, one that’s legitimate and one that’s supposed to simulate an attacker’s attempt to inject malicious code in one of your assets. As you can see, the attacker’s attempt proceeds without any issue when SRI is turned off:
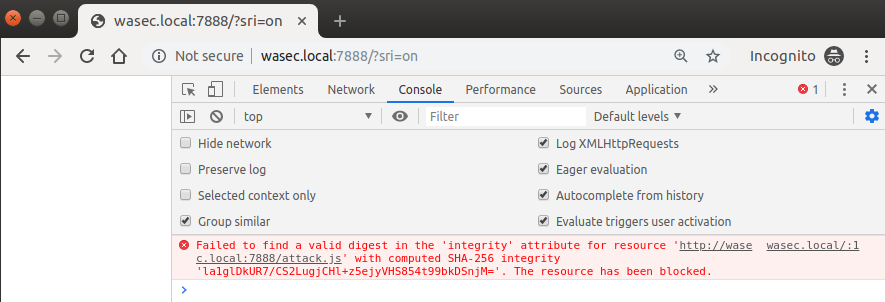
By visiting http://wasec.local:7888/?sri=on we get a completely different outcome, as the browser realizes that there’s a script that doesn’t seem to be genuine, and doesn’t let it execute:
Here is what our HTML looks like when SRI is turned on:
A very clever trick from browser vendors, and your users are secured should anything happen to the files hosted on a separate CDN. Clearly this doesn’t prevent an attacker from attacking your “main” resource (ie. the main HTML document), but it’s an additional layer of security you couldn’t count on until a few years ago.
The slow death of EV certificates
More than once in my career I’ve been asked to provision an EV certificate for web applications I was managing, and every single time I managed my way out of it — not because of lazyness, but rather due to the security implications of these certificates. In short? They don’t have any influence on security, and cost a whole lot of money: let’s try to understand what EV certificates are and why you don’t really need to use one.
Extended Validation certificates (abbr. EV) are a type of SSL certificates that aims to increase the users’ security by performing additional verification before the issuance of the certificate. This additional level of scrutiny would, on paper, allow CAs to prevent bad actors from obtaining SSL certificates to be used for malicious purposes — a truly remarkable feat if it would actually work that way: there were some egregious cases instead, like the one where a researcher named Ian Carrol was able to obtain an EV certificate for an entity named “Stripe, inc” from a CA. Long story short, CAs are not able to guarantee an increased level of security for EV certificates.
If you’re wondering why are EV certificates still a thing to this day, let me give you a quick answer: under the false assumption of “added security”, EV certificates used to have a special UI in browsers, sort of a “vanity” feature CAs would charge exorbitant amount of money for (in some cases more than $1000 for a single-domain EV certificate). This is how an EV certificate would show up in the user’s browser:
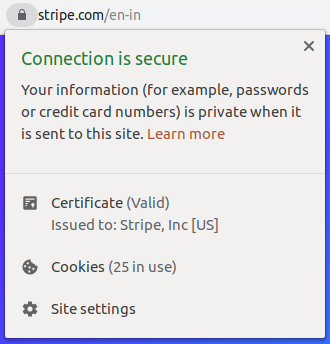
As you can see, there is a “nice” UI pattern here, with the problem being that it is of no use from a security perspective. As soon as research after research started to point out how ineffective EV certificates are, in terms of security, browsers started to adapt, discouraging websites from purchasing EV certificates. This is how the browser bar looks like when you access stripe.com from Chrome 77 onwards:
The additional information (such as the organization’s name) has been moved to the “Page Info” section, which is accessible by clicking on the lock icon on the address bar:
Mozilla has implemented a similar pattern starting with Firefox 70, so it’s safe to safe you shouldn’t bother with EV certificates anymore:
they do not offer any increased level of security for your users
they do not get a “preferential” UI at the browser-level, making it a very inefficient expense compared to regular SSL certificates you can obtain (Let’s Encrypt certificates are free, for example)
Troy Hunt summed the EV experience quite well:
EV is now really, really dead. The claims that were made about it have been thoroughly debunked and the entire premise on which it was sold is about to disappear. So what does it mean for people who paid good money for EV certs that now won’t look any different to DV? I know precisely what I’d do if I was sold something that didn’t perform as advertised and became indistinguishable from free alternatives…
Paranoid mode: on
Remember: being paranoid might sometime cause a scoff from one of your colleagues or trigger their eye roll, but don’t let that deter you from doing your job and making sure the right precautions are being taken.
Some users, for example, do not appreciate enforcing 2FA on their account, or might not like to have to CC their manager in an email to get an approval, but your job is to make sure the ship is tight and secure, even if it means having to implement some annoying checks or processes along the way. This doesn’t mean you should ask your colleagues to get a notary public to attest their printed request for a replacement laptop, so always try to be reasonable.
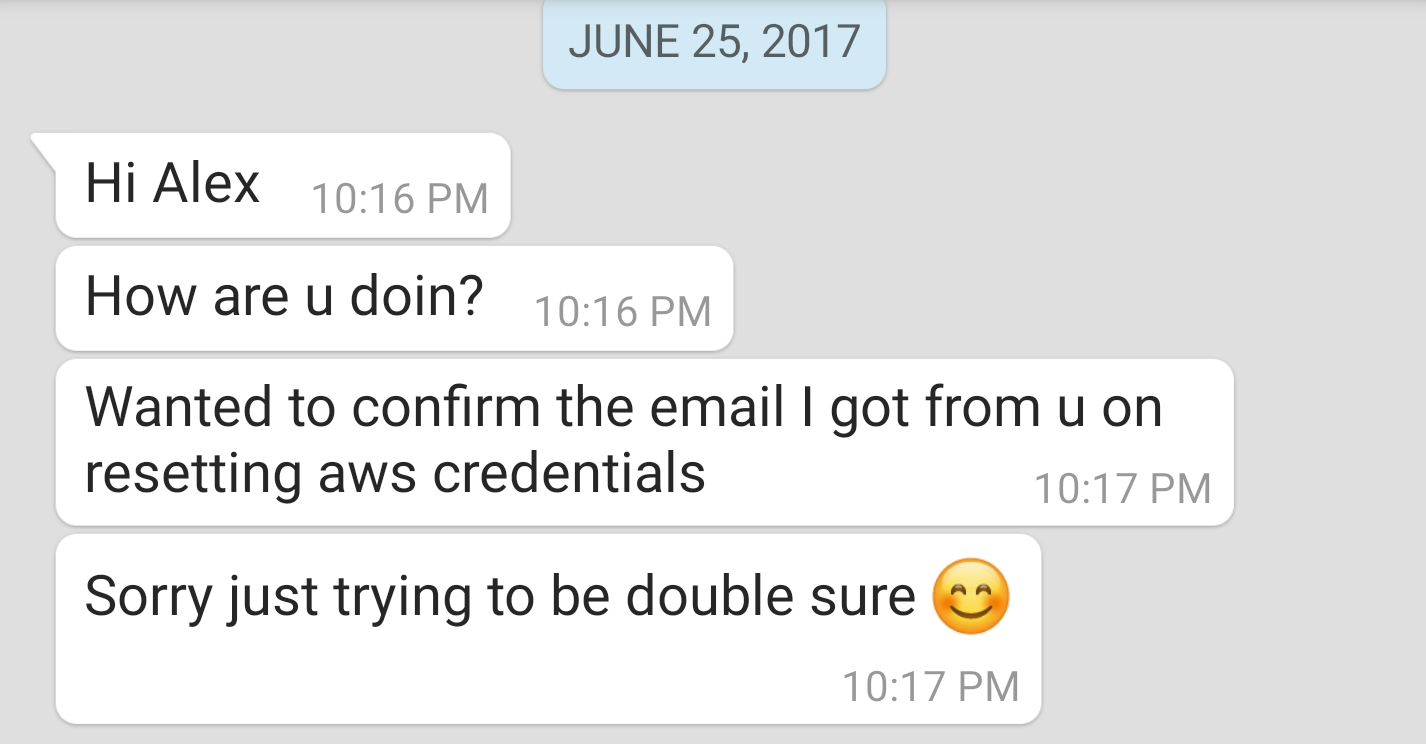
I still remember being locked out of an AWS account (I stupidly let my password expire) and having to ask our Lead System Administrator for a password reset with an email along the lines of “Hi X, I’m locked out of my AWS account, can you reset my password and share a new, temporary one here?”.
The response? A message on WhatsApp:
This was the right thing to do, as a person with malicious intentions could have just gotten a hold of my email account and try to steal credentials by posing as me. Again, being paranoid is often times a virtue.
Low-priority and delegated domains
What is Google?
A search engine you might say, but then you’d find yourself thinking about the vast amount of products that they offer and quickly realize Google is a conglomerate that offers a growing number of products, starting with household names such as Maps to little-known services like Keep or Chrome Remote Desktop.
You might be wondering where we’re headed, so let me clarify that right now: the organization you work for probably has more than one service it offers to customers, and those services might not really be related to each other. Some of them, for example, could be low-priority ones the company works on, such as a corporate or engineering blog, or a URL shortener your customers can use alongside other, far bigger services you offer. Often, these servics, sit on a domain such as blog.example.com.
“What’s the harm?”, you say. I would counter that using your main domain to store low-priority services can harm your main business, and you could be in for a lot of trouble. Even though there’s nothing inherently wrong with using subdomains to serve different services, you might want to think about offloading low-priority services to a different domain: the reasoning behind this choice is that, if the service running on the subdomain gets compromised, it will be much harder for attackers to escalate the exploit to your main service(s).
As we’ve seen, cookies are often shared across multiple subdomains (by setting the domain attribute to something such as *.example.com, .example.com or simply example.com), so a scenario could play out where you install a popular blogging software such as WordPress on engineering-blog.example.com and run with it for a few months, forgetting to upgrade the software and install security patches as they get published. Later, an XSS in the blogging platform allows an attacker to dump all cookies present on your blog somewhere in his control, meaning that users who are logged onto your main service (example.com) who visit your engineering blog could have their credentials stolen. If you had kept the engineering blog on a separate domain, such as engineering-blog.example.io, that would not have been possible.
In a similar fashion, you might sometime need to delegate domain to external entities, such as email providers — this is a crucial step as it allows them to do their job properly. Sometimes, though, these providers might have security flaws on their interfaces as well, meaning that your users, on your domains, are going to be at risk. Evaluate if you could move these providers to a separate domain, as it could be helpful from a security perspective. Assess risks and goals and make a decision accordingly: as always, there’s no silver bullet.
OWASP
Truth to be told, I would strongly recommend you to visit the OWASP website
and find out what they have to say:
OWASP Cheat Sheet Series (https://cheatsheetseries.owasp.org): a collection of brief, practical information. You can find inspiring articles such as how to harden Docker containers or in what form should passwords be stored. It is a very technical and comprehensive list of guides that inspired the practical approach used in this chapter of WASEC
OWASP Developer Guide (https://github.com/OWASP/DevGuide): a guide on how to build secure applications. It is slowly being rewritten (the original version was pubished in 2005) but most of the content is still very useful
These are 3 very informative guides that should help you infusing resistance against attacks across your architecture, so I’d strongly suggest going through them at som point in time. The Cheat Sheet Series, in particular, is extremely recommended.
Hold the door
Now that we went through a few common scenarios you might be faced with in your career, it’s time to look at the type of attack that has garnered the most attention in recent years due to the widespread adoption of both cloud computing and IoT devices, allowing attackers to create armies of loyal soldiers ready to wreck havoc with our networks.
They are distributed, they are many, they grow in intensity each and every year and represent a constant treat to public-facing companies on the internet: it’s time to look a DDOS attacks.
]]>
<![CDATA[Command line spinners: the magic tale of modern typewriters and terminal movies]]>2019-09-22T06:54:00+00:00https://odino.org/command-line-spinners-the-amazing-tale-of-modern-typewriters-and-digital-movies
]]>
In the latest release of ABS, we introduced a package manager
that fetches an archive from GitHub and installs it locally:
like in many other command-line interfaces, we decided to
add a “loader” to accompany the process, something that looks
like this:
I want to take a moment to reflect on how we implemented
the simple spinner you see in the video, a process that derives
from typewriters and movies — let’s get to it!
We’re going to see a picture???
My wife usually refers to movies as pictures, something that leaves me
confused as I’m not familiar with the term. But
when you think about it, we’re often dealing with the same term in the
context of award winning movies — who won best picture at the last
academy awards?
This happens because movies, in their essence, are simply a collection
of pictures stitched together, put in motion to give us the illusion
of something happening in front of our eyes while, in reality, it’s just
a very quick passing of images, aided by sounds, that trick us into
believing a story is unfolding in front of our eyes.
Now, we said we wanted to create a command-line spinner, and you can
probably see where I’m going already: we can borrow the very same concept
of motion picture and apply it to the command-line — have a few different
characters (pictures) that are swapped very quickly to give us the illusion
of an animation, kinda like this:
The list of characters, or “pictures”, we’ve used in this sequence is
['⠋', '⠙', '⠹', '⠸', '⠼', '⠴', '⠦', '⠧', '⠇', '⠏'], but you can
try this one out yourself by playing around in the example below, where
you decide both the speed of the “animation”, as well as the characters
involved (I’m using these unicode characters in this example):
THIS SPINS
Enter the list of comma-separated characters:
Enter the speed at which characters rotate (in ms):
Now, it should be very clear what the mechanics behind spinners
are, but we’re still missing one key element — on the command line, how can
we “override” the previous characters? This is no HTML, where a simple
document.getElementById("id").innerHTML = "myNewChar" does the trick,
this is the CLI we’re talking about.
This example illustrates the problem we’re talking about:
Enter good old fashioned typewriters.
Carriage returns
Hey there! Have you ever set your hands on an old-school typewriter?
If you say “it’s all good” rather than “it’s all gucci”,
chances are you’re old enough to have, at least, seen one of them. I’ve
personally never used one, but a mechanism they use is the basis of how modern terminals
allow you to replace content inline.
This animation by Haley Schbeeb gives you a little bit more context —
watch closely what happens when the typewriter reaches the end of the line:
It “resets”, right? This mechanism is called “carriage return” and it’s best explained by
Wikipedia:
Originally, the term “carriage return” referred to a mechanism or lever on a typewriter. For machines where the type element was fixed and the paper held in a moving carriage, this lever was operated after typing a line of text to cause the carriage to return to the far right so the type element would be aligned to the left side of the paper. The lever would also usually feed the paper to advance to the next line.
Now, typewriters need to advance one line (“line feed”) as well as reset their
position to the far left of the paper (“carriage return”). The same exact mechanisms can
be applied to your terminal too: these two operations are done through the characters
\n and \r.
Nowadays, most systems consider \n the equivalent of \n\r,
but understanding how these characters work is important to fully grasp how to
replace a character in your terminal: \n will “move the cursor down one line”,
while \r will move it all the way back to the starting position of the current
line.
With this understanding, we will now be able to create a CLI spinner using this
simple loop:
print character X
print a carriage return (\r): the cursor is moved back to the beginning of the line
print character Y, it will override character X since they’re printed at the same position
Put it altogether
The simple example I’m going to use is written in Go, but you could build it
in virtually any programming language. What we need to do is to simply start with a
list of characters, then print one of them at a time, followed by a carriage
return, so that the next character will be printed in place of the current one:
]]>
<![CDATA[My last day at Namshi: goodbye folks!]]>2019-09-15T19:42:00+00:00https://odino.org/goodbye-namshi
]]>
Today, I wave goodbye to the company I supported for the past 7 and
a half years, Namshi.
It’s with mixed feeling that I write this blog post, as it’s been
a hell of a ride and I recognize I was privileged to get on board
just at the right time. It is a truly
bittersweet moment to leave behind something you’ve dedicate so much
to, but I do feel my time is now: after all of these years I long for a change
of scenery, (somewhat) different challenges and new environment
to flourish in. It won’t be easy to replicate what we’ve done over
the past years, but the least I can do is to try to spread all the
good I’ve experienced.
To all my teammates, I thank you for striving to make this
happen: we wouldn’t have come anywhere near to where we are right now
if it wasn’t for the collective team effort we put over the years.
This is a “thank you” that spans 7 years of life, so it goes to the
the current team as much as it goes to the ones who were there in
2012, when it was real wild. From the warehouse to HQ, your work
was impressive, and it’s a great story in the region.
I want to take a moment to mention the folks
in the tech team, as their loyalty and
effort have ignited my days for years — if it wasn’t for what
my teammates have been putting in day in and day out, I don’t think
I could have lasted this long.
Among all of the positive qualities that this tech team developed,
there’s one I want to call out: the generosity that is embedded in this team’s
DNA is what is going to make me proud for years to come, as how much
each and every individual strives to help their teammates is something
I haven’t experienced before. I am truly happy to say that
we are a team of great software engineers but, way before that,
great human beings.
As for myself, I will take a break, and focus on the next crazy ride
right after. I’m not planning to get back to work for at least another couple
of months, and I haven’t finalized anything yet. What I can say, though,
is that I’m not planning to sit down and discuss new opportunities as I’ve
already done that and have shortlisted my options. I’m excited about this
ambiguity and, more importantly, I’m excited about spending my next
couple of months relaxing, recharging my batteries and waiting to see
the future unfold in front of me.
Bye folks, it’s been a pleasure.
]]>
<![CDATA[ABS 1.7.0: ctrl+r and other optimizations]]>2019-08-30T19:15:00+00:00https://odino.org/abs-1-dot-7-0-ctrl-plus-r-and-other-optimizations
]]>
A few days ago I released a new minor version of the ABS
programming language, 1.7.0,
which adds some syntactic sugar as well as improvments to
the REPL — let’s get to them!
Reverse search in the REPL through ctrl+r
You can type something in the REPL and, by pressing
ctrl+r, ABS will try to find the last command that
was executed that matches what you typed.
See it in action:
If you press ctrl+r multiple times, the REPL will
walk its way back into the history to find the previous
command matching your input, until it reaches the end
of the history.
This feature has been implemented thanks to some improvements
in go-prompt, so hats off to
Masashi Shibata for helping out!
Number abbreviations
Easily my favorite, this feature allows you to append a suffix to a
number in order to specify the “order of magnitude” of the number itself.
Confused? It’s actually quite simple:
Suffixes are case-insensitive, so you can express 1000000
with either 1m or 1M.
Improvements to some builtin functions
We’ve decided to ease using some of the standard functions:
you can now, for example, print a message before exiting
a script directly through the exit function.
Your code would have previously looked like:
1234
iferr{echo("an error occurred, goodbye!")exit(1)}
while now you can simply do:
123
iferr{exit(1,"an error occurred, goodbye!")}
Similarly, we made it easier to use the replace function on
strings: you can now omit the last argument (number of replacements),
with its default value being -1 (no limit):
12345
"aaa".replace("a", "b", -1)# "bbb"# is now the same as"aaa".replace("a", "b")# "bbb"
and you can now also specify a list of characters to replace:
]]>
<![CDATA[ABS 1.6.0: the convenience of index ranges and default return values]]>2019-08-18T18:15:00+00:00https://odino.org/abs-1-dot-6-0-the-convenience-of-index-ranges-and-default-return-values
]]>
Here we are with a new release of ABS, the elegant programming language
for all of your scripting needs!
Even though small, 1.6 (with 1.6.0
and 1.6.1) introduces a
couple interesting features, so let’s check them out!
Index ranges
You can now access ranges within strings and arrays by using the
popular [start:end] syntax: [1,2,3,4][0:2] will return [1,2].
Start and end can be ommitted — you could simplify the expression
above with [1,2,3,4][:2].
Default return values
You can now simply use a return; at the end of a function, and
it will return the default value null:
12345
fn=f(){return;}echo(fn())
Deprecation of $(…)
If you’ve followed ABS since its initial release, chances are you first
used system commands through the $(command) syntax: we’ve now deprecated
it and make sure the documentation reflects the fact that `command`
is the standard, preferred way to run commands.
Now what?
Install ABS with a simple one-liner:
1
bash<(curlhttps://www.abs-lang.org/installer.sh)
…and start scripting like it’s 2019!
]]>
<![CDATA[The ABS playground: run ABS code directly in your browser (WHOOOOP!)]]>2019-08-17T18:45:00+00:00https://odino.org/the-abs-playground-run-abs-code-directly-in-your-browser-whoooop
]]>
Remember the last time you thought “ough, JavaScript”?
Well, that’s me every other day: I love JS for
its flexibility and dynamism, but I also sometimes find
it painful to deal with, especially in some
specific programming contexts.
If you, like me, hoped to be able to write
something other than JavaScript in order to get
stuff done on the web, chances are you bumbed
into WebAssembly (abbr. WASM),
and considered it your holy grail. WASM
is a portable binary format that’s been
implemented by all major browsers and
allows other languages to be compiled for the
web.
Why is that important? Well, that’s the key
of how I managed to run an ABS playground
(a code runner) on the browser.
The original issue
One of ABS’ main contributors, Ming, smartly
suggested that it would be interesting to let
users play around with ABS without having it
installed on their systems.
My first thought was to replicate the Go playground,
but that would have meant setting up a server-side
code-runner, and that would have required
more time (maintenance) and money (server cost)
that we had on hand.
We abandoned the idea of a code runner for a while,
until we thought of something creative…
WASM to the rescue
Go recently added support for WASM
as one of its compilation targets, meaning you can
run Go applications on the browser — you just
need a simple GOOS=js GOARCH=wasm go build -o script.js script.go
and you’re set with an executable that can run within the
browser.
I then thought: what if we could compile the ABS interpreter,
which is purely written in Go, to WASM?
The downside of compiling Go into WASM is that the
binaries are a bit heavy (ABS is 4.3 MB),
but, considering that this is more of a proof-of-concept
than a serious attempt to run ABS in the browser, I
can’t really complain.
Armed with a distribution of the ABS interpreter that
can run within your browser, I then setup a silly HTML
page in our docs
that would load the WASM binary and give you a textboxt
to play around, which brings me to the big announcement…
You can try most of ABS’ features directly in
the web editor: simply write some code, hit
Ctrl+Enter and see the result pop in front
of your eyes!
Let me know if you have any feedback!
]]>
<![CDATA[Playing with QuickJS]]>2019-07-23T12:14:00+00:00https://odino.org/playing-with-quickjs
]]>
A few days ago Fabrice Bellard released
QuickJS, a small JS engine that
targets embedded systems.
Curious to give it a try, I downloaded and set it up on my system
to try and understand this incredible piece of software.
Installation
Setting up QuickJS is dead simple:
clone one of the Github mirrors with git clone git@github.com:ldarren/QuickJS.git
cd QuickJS
make
…and that’s it: the installation will leave you with a few
interesting binaries, the most interesting one being qjsc,
the compiler you can use to create executables out of your JS
code.
Trying it out
Let’s try to write a simple script that calculates powersets
for a given list:
Well, QuickJS’ standard library is fairly limited at the moment,
meaning you won’t be able to use most NPM modules or the NodeJS standard
library since it’s not really implemented: QuickJS simply implements
the ES2019 specification, which doesn’t include any kind of standard
item you might be used to, like require or process.
The full documentation for QuickJS is available here,
and you will notice that the only standard objects you can work with
are std and os — very limited when compared to other, fully-bloated
engines but useful nevertheless (again, you have to think of QuickJS as an
engine to be embedded, and not something you can use to write your next
web app).
Still, quite an impressive piece of work!
]]>
<![CDATA[ABS 1.5.0: file writers have landed!]]>2019-07-16T19:00:00+00:00https://odino.org/abs-1-dot-5-0-file-writers-have-landed
]]>
A few hours ago I released a new minor version of the ABS programming
language, 1.5.0,
which includes a couple of interesting features — let’s get to them!
File writers
Probably one of the most exciting things coming out of this release
are file writers: > and >>.
We finally implemented break and continue
within for loops: earlier on you could use return
to exit a loop but it always felt a tad awkward —
with this release this has been fixed.
We also fixed a bug that resulted in a stack overflow when looping
a high number of times in a for..in loop:
123
$ for x in 1..10_000_000 { 1 & 2 }runtime: goroutine stack exceeds 1000000000-byte limit
fatal error: stack overflow
This has been fixed. As a bonus point, for..in loops are
also significantly faster with this change (especially noticeable
on larger loops, at around 30% faster):
]]>
<![CDATA[ABS 1.4.0: welcome unicode!]]>2019-07-15T19:00:00+00:00https://odino.org/abs-1-dot-4-0-welcome-unicode
]]>
A few weeks ago I released version 1.4.0 (and 1.4.1, with an additional bugfix)
of the ABS programming language: in this post, I’d like to explain everything
major that made it in this new minor release.
ABS ❤ unicode
We have implemented unicode in ABS: you can now use both
unicode letters in variable names as well as any
unicode character in strings.
For example, you can output any code point within a string:
ȼ="this is a weird c"echo(ȼ)// "this is a weird c"
Note that only unicode letters (category L) are allowed as variable
names, and using any other character will result in a parsing error:
1234
⧐❤=aparsererrors:Illegaltoken'❤'[1:1]❤=a
eval(…)
Oh, good old-school eval!
This function does exactly what you’d expect it to do, as it executes
the ABS code passed as its argument:
123
test=[1,2,3,4]eval("test.len()")// 4eval("test.len()").type()// NUMBER
Digits in variable names
We now support digits in variable names:
1
v4r14bl3="I got numbers"
We might expand this feature later on to include unicode numbers,
if the community feels like this would be a useful feature (haven’t
heard of any use case so far).
Numeric separators
Following Python 3.6
and JS on Chrome 75,
we’ve decided to help with readability on large numbers and allow
_ as a numeric separator:
1234567
// beforeten_grands=10000ten_yards=10000000// now you can...ten_grands=10_000ten_yards=10_000_000
Panic without a terminal
We fixed a panic when you try to run the ABS REPL without
having a terminal attached (for example, during a Docker
build, or when piping a bare abs command); ABS will now
explicitely let you know what the problem is:
There was an issue when converting keys or values with
double quotes in them, but it has since been fixed.
Code such as '{"x": "\"y"}'.json().x will now work
seamlessly.
Go modules
We’ve migrated the codebase to Go modules:
even though this might not be a ground-breaking change, it should
help those who develop the ABS core, allowing no conflicts when it
comes to dependencies.
Now what?
Install ABS with a simple one-liner:
1
bash<(curlhttps://www.abs-lang.org/installer.sh)
…and start scripting like it’s 2019!
PS: Again, many thanks to Ming,
who’s been taking a larger role as the weeks went by. Without her,
many of the stuff included in 1.4 wouldn’t be possible!
PPS: 1.5.0 is already well underway — expect
it in the next few days. We’ll be introducing extremely
interesting features such as file writers, so it’s going
to be an exciting release!
]]>
<![CDATA[ABS 1.3.2: making ABS faster with a simple fix]]>2019-06-05T20:36:00+00:00https://odino.org/abs-1-dot-3-2-making-abs-faster-with-a-simple-fix
]]>
Hi there! Just a quick post to announce a bugfix release of the ABS programming
language: 1.3.2 fixes a simple yet important performance bug dealing
with short-circuit evaluation.
Short-circuiting is the amazing property some languages assign
to boolean operators (eg. && or ||): if the first parameter
in the expression is sufficient to determine the end value of
the expression, the second value is not evaluated at all.
Take a look at this example:
1
false&& sleep(a_really_long_time)
You wouldn’t expect the script to sleep since the first parameter
in the expression is already falsy, thus the expression can never be
truthy.
What about:
1
true|| sleep(a_really_long_time)
Same thing, easy peasy.
Even more important, short-circuiting can be really useful in order
to access a property when not sure whether it exists:
12
# we don't know whether X is null or whatx && x.property
Compare that to what you’d usually have to write:
123456
# we don't know whether X is null or whatif x {return null
}return x.property
You might be wondering what does all of this have to do with ABS:
well, we were supposed to have fully working short-circuiting but,
as it turns out, there was a bug preventing this from working. Your
code would work and run successfully, but it would always evaluate
all the arguments of an expression, even if it short-circuited. In
some cases (like when using short-circuiting for accessing properties)
your code would crash — defeating the whole purpose of short-circuiting.
Luckily, Ming fixed this in #227
and the fix got backported to the 1.3.x branch: 1.3.2 is served!